In this post, I share my journey transitioning from Amazon Linux 2 to Bottlerocket as the EKS node OS, aiming for enhanced security with a hardened OS image.


In my envionment, running Kubernetes workloads on Amazon EKS with Amazon Linux 2 (AL2) worker nodes is a tried-and-tested approach. It’s stable, compatible with most tooling, and offers the flexibility of a general-purpose Linux OS.
AL2 is a full Linux distribution meaning it ships with many binaries, libraries, and utilities that aren’t strictly needed for running containers. This fully blown OS increases the attack surface if not hardened properly. If an attacker compromises a node (through a container escape, misconfiguration, or another vector), these extra tools and privileges can be leveraged for deeper intrusion, persistence, and lateral movement.
Hence, it was a wise choice to explore Bottlerocket which is CIS hardened out of the box as a EKS node OS.
Bottlerocket: Minimal, Secure, Container-First OS
Bottlerocket is an open-source Linux-based OS purpose-built by AWS to run containers securely and with minimal overhead. It’s now officially published and supported for EKS and ECS, making it a good alternative to AL2 for containerization platforms. As Bottlerocket is CIS hardened out of the box, it saves so much of manual/automation work of hardening OS image.
Key Security Advantages of Bottlerocket over AL2
- Immutable Root File System
- The root filesystem is read-only and protected with
dm-verity(integrity verification).
- The root filesystem is read-only and protected with
- No Direct Package Installation
- There’s no package managers (yum/apt).
- All additional functionality runs in special-purpose containers (
controloradmincontainer), isolating changes from the host OS.
- No Default SSH Access
- Bottlerocket blocks SSH by default.
- Administrative access is through AWS Systems Manager (SSM) Session Manager, meaning you are covered with IAM and CloudTrail.
- Locked-Down System & Kernel
- No direct
systemdor kernel-level access from workloads. - The OS is configured and updated via a local API (protected by SELinux policies), avoiding risky manual edits.
- No direct
- Atomic, Signed OS Updates with Rollback
- Updates are applied as a full image to an inactive partition, verified with cryptographic signatures, and made active only after reboot.
Why BottleRocket could be a good choice?
Moving from AL2 to Bottlerocket removes unnecessary OS-level tools and privileges from your nodes, reducing the blast radius. Instead of manually hardening AL2 with CIS benchmarks, SELinux policies, and SSH lockdowns, Bottlerocket bakes these controls in by default.
This means:
- Lower operational risk.
- Less maintenance effort to stay compliant.
- Better alignment with Kubernetes’ container-first security model.
Official Bottlerocket Documentation → https://bottlerocket.dev/en/os/1.42.x/
Our Migration Journey with Karpenter
In the earlier section, we discussed why we focused on Bottlerocket. Now, let’s talk about the how the actual activities we performed during our migration.
Our EKS cluster uses Karpenter for node provisioning instead of EKS-managed node groups. Hence this post focuses on Karpenter-specific configurations for using Bottlerocket AMIs.
Let’s get into the stepwise procedure –
1. Updating the EC2NodeClass Manifest
To provision Bottlerocket nodes with Karpenter, we updated our EC2NodeClass manifest as follows:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: bottlerocket-nodes
spec:
amiFamily: Bottlerocket
amiSelectorTerms:
- alias: bottlerocket@v1.42.0
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
encrypted: true
kmsKeyID: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx
volumeSize: 10Gi
volumeType: gp3
- deviceName: /dev/xvdb
ebs:
deleteOnTermination: true
encrypted: true
kmsKeyID: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx
volumeSize: 30Gi
volumeType: gp3
Key Points
amiFamilymust be set toBottlerocket.amiSelectorTerms.aliasspecifies the desired Bottlerocket version.- Avoid using
bottlerocket@latestin production environments. As it points to an AWS-managed SSM parameter, if AWS updates the parameter value, Karpenter detect it as an AMI drift and recycle nodes (default check interval is 1 hour). It shuffles all the PODs in the cluster.
Pro tip: Instead of relying on @latest, you can implement your own AMI automation pipeline. Tag new AMIs with predefined keys (e.g., owner=myteam, version=1.42.0) and reference those tags in amiSelectorTerms.
2. Understanding Block Device Mappings
We explicitly defined two block devices for Bottlerocket nodes:
/dev/xvda— OS Volume- For Bottlerocket OS!
- Contains active/passive partitions, bootloader,
dm-veritymetadata, and the Bottlerocket API datastore.
/dev/xvdb— Data Volume- Used for everything running on top of Bottlerocket i.e. container images, runtime storage, and Kubernetes persistent volumes.
If you don’t define /dev/xvdb in your manifest:
- Karpenter defaults it to 20 GB of type GP2. I prefer
gp3for best price-performance ratio. - You may end up in insufficient disk space incidents.
/dev/xvdamay end up larger than necessary, wasting EBS storage for the OS.
By making these changes, we were able to seamlessly migrate from AL2 to Bottlerocket in our Karpenter-managed EKS environment, gaining all the hardened security benefits without disrupting workloads.
3. User Data Script: Custom GuardDuty DNS Mapping on Bottlerocket
Background
In our setup, EKS cluster uses a self-hosted DNS instead of AWS’s default DNS. We’ve also enabled AWS GuardDuty threat detection for the cluster.
When GuardDuty protection is enabled, it creates a PrivateLink VPC endpoint whose DNS name is resolved inside the respective PODs. This PrivateLink is available in the subnets/AZs where it’s created (in our case: 3 subnets, AZs a, b, and c).
For GuardDuty’s DaemonSet to function correctly, all EKS nodes must be able to resolve its PrivateLink endpoint from within the same subnet they launched in.
How We Did It on AL2
On Amazon Linux 2, this was simple:
- Add a shell script to EC2 user data.
- Script fetchs the subnet-specific PrivateLink IP.
- Appends the mapping to
/etc/hosts.
The Bottlerocket Challenge
Bottlerocket can not execute raw shell scripts directly via EC2 user data.
Instead:
- It uses TOML-formatted user data.
- OS changes are made through the Bottlerocket API (
apiclient).
Also, /etc/hosts exists on the read-only root filesystem, so direct edits are not possible.
Our Solution
After researching the Bottlerocket design, we found three possible approaches:
- Host containers (
admin,control): Could run the script butadminrequires enabling an SSH keypair, which we wanted to avoid. - Bootstrap containers: Run a container at instance boot before the
kubeletstarts. - apiclient API calls: The correct way to update
/etc/hostson Bottlerocket.
We opted to go ahead with bootstrap containers + apiclient.

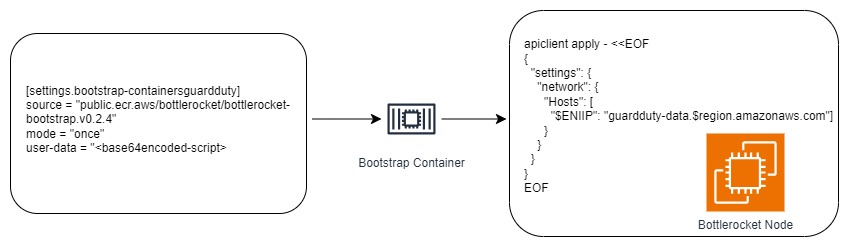
Final User Data Configuration
Here’s the relevant part of our EC2NodeClass manifest for Karpenter:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: bottlerocket-guardduty
spec:
amiFamily: Bottlerocket
amiSelectorTerms:
- alias: bottlerocket@v1.42.0
blockDeviceMappings:
...
userData: |
[settings.bootstrap-containers]
[settings.bootstrap-containers.guardduty]
source = "public.ecr.aws/bottlerocket/bottlerocket-bootstrap:v0.2.4"
mode = "once"
user-data = "xxxvYmlxxxxxxxxxxxxxxxxxxxxxxxyBXT1JMXX=="
Note: The base64-encoded string shown in the bootstrap-container user-data is only a placeholder. Below are the detailed steps to generate the actual base64-encoded string for your script.
Implementation Steps
a) Create the shell script (myscript.sh)
This script uses apiclient to inject the GuardDuty PrivateLink mapping into /etc/hosts via the Bottlerocket API.
#!/bin/bash
set -euo pipefail
echo "[BOOTSTRAP] Starting GuardDuty host entry setup..."
# Get IMDSv2 token
TOKEN=$(curl -sX PUT "http://169.254.169.254/latest/api/token" \
-H "X-aws-ec2-metadata-token-ttl-seconds: 60")
# Get metadata
MAC1=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/network/interfaces/macs/ | head -1 | tr -d '/')
VPCID=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/network/interfaces/macs/$MAC1/vpc-id)
AZ=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/dynamic/<AWS-ACCOUNT-ALIAS>/document | jq -r .availabilityZone)
REGION=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/dynamic/<AWS-ACCOUNT-ALIAS>/document | jq -r .region)
# Get GuardDuty ENI IP
ENIIP=$(aws ec2 describe-network-interfaces \
--filters Name=vpc-id,Values=$VPCID \
Name=availability-zone,Values=$AZ \
Name=group-name,Values="GuardDutyManagedSecurityGroup-vpc-*" \
--query 'NetworkInterfaces[0].PrivateIpAddress' \
--region "$REGION" --output text)
if [[ -z "$ENIIP" || "$ENIIP" == "None" ]]; then
echo "[BOOTSTRAP] No GuardDuty ENI IP found"
exit 0
fi
cat > hosts.json <<EOF
{
"settings": {
"network": {
"hosts": [
["$ENIIP", ["guardduty-data.$REGION.amazonaws.com"]]
]
}
}
}
EOF
apiclient apply < hosts.json
b) Encode the script in Base64
Bootstrap container user data must be Base64-encoded for TOML.
base64 -w 0 myscript.sh
c) Embed the Base64 string in user data
Paste the encoded string into:
[settings.bootstrap-containers.guardduty]
user-data = "<base64-encoded-script>"
d) Validate execution
You can verify your bootstrap container ran successfully using:
aws ec2 instance --> Actions --> Monitor and Troubleshoot --> Get system logKey Takeaways:
- Use the
network.hostsAPI setting for modifying contents of/etc/hosts - Bootstrap containers are the best way to run initialization scripts at boot.
- Avoid enabling the
adminhost container with SSH just for automation, it defeats the purpose of Bottlerocket’s out of the box hardening.
Final Thoughts
In this blog, we’ve shared the insights and hands-on learnings we’ve gathered while working with Bottlerocket. Since there’s limited practical guidance available online, we thought to share our experience. In a summary: migrating from Amazon Linux 2 to Bottlerocket for EKS node hardening not only strengthens security but also changes how we interact with the underlying OS. While certain tasks like running userdata scripts require a different approach, Bottlerocket’s design ensures a minimal attack surface, immutable infrastructure, and tighter control over system access. With the right methods, such as leveraging bootstrap containers and the Bottlerocket API, you can still meet your operational requirements without compromising on security.