
An article to overview SRR and CRR in Amazon S3. Why, when, and how to use it.


Amazon S3 is a Simple Storage Service offered by AWS. It’s object storage with virtually unlimited in size. S3 also offered the feature of replication to replicate objects from one bucket to another bucket. The bucket is a placeholder for arranging objects in S3. It can be visualized as a root folder in the file structure.
What is replication in Amazon S3?
Replication is a process of copying objects and their metadata from a source bucket to a destination bucket in an asynchronous way in the same or different region.
Why S3 replication is needed?
There are couple of use cases where S3 replication can prove helpful –
- Compliance: Some customers need to keep a copy of data in a particular territory for compliance purposes. In such cases, S3 replication can be set to copy data into the destined region.
- Data copy under different regions and accounts: S3 data replication enables users to copy data in different regions and under different accounts.
- Latency requirement: Keeping a copy in a region close to consumers helps to achieve low latency in accessing data stored in S3.
- Objects aggregation: Data from different buckets can be aggregated into a single bucket using replication.
- Storage class requirement: S3 replication can directly put objects in Glacier 9diff storage class) in the destination bucket.
Types of S3 replications
- Same-Region Replication (SRR)
- Source and destination buckets lie within the same region.
- Used in case data compliance requires the same copy of data to be maintained in different accounts.
- Log aggregation can be achieved using SRR by setting up SRR from different log buckets to the same destination bucket.
- Cross-Region Replication (CRR)
- Source and destination bucket lies in different regions.
- Used in case data compliance requires the same copy of data to be maintained in different regions.
- Useful in latency requirements.
Requirements and limitations of Amazon S3 replication
- Versioning must be enabled at source and destination buckets.
- Existing files are not replicated. Only new uploaded objects (after enabling replication) are replicated.
- Delete markers created by lifecycle rules are not replicated.
- You can’t replicate objects which are encrypted using SSE-C.
- Can set up across accounts.
- It’s one-way replication, not bidirectional. It means source bucket to destination and not vice versa.
- Lifecycle policy events are not replicated.
- Amazon S3 should have access to read/write on both buckets by assuming your identity.
- The destination bucket can not be configured with requestor pays mode.
How to configure S3 replication?
Let’s dive into the practical aspects of it. We will be configuring replication between 2 buckets hosted in different regions under the same account for this exercise. Read here how to create an S3 bucket. Below are 2 buckets in consideration –

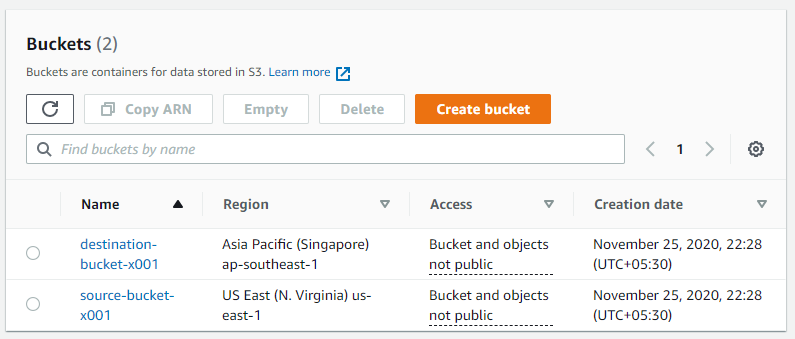
- Log in to the S3 console.
- Click on Buckets in the left navigation panel.
- On the buckets page, click on the bucket name you want to create replication (source bucket).

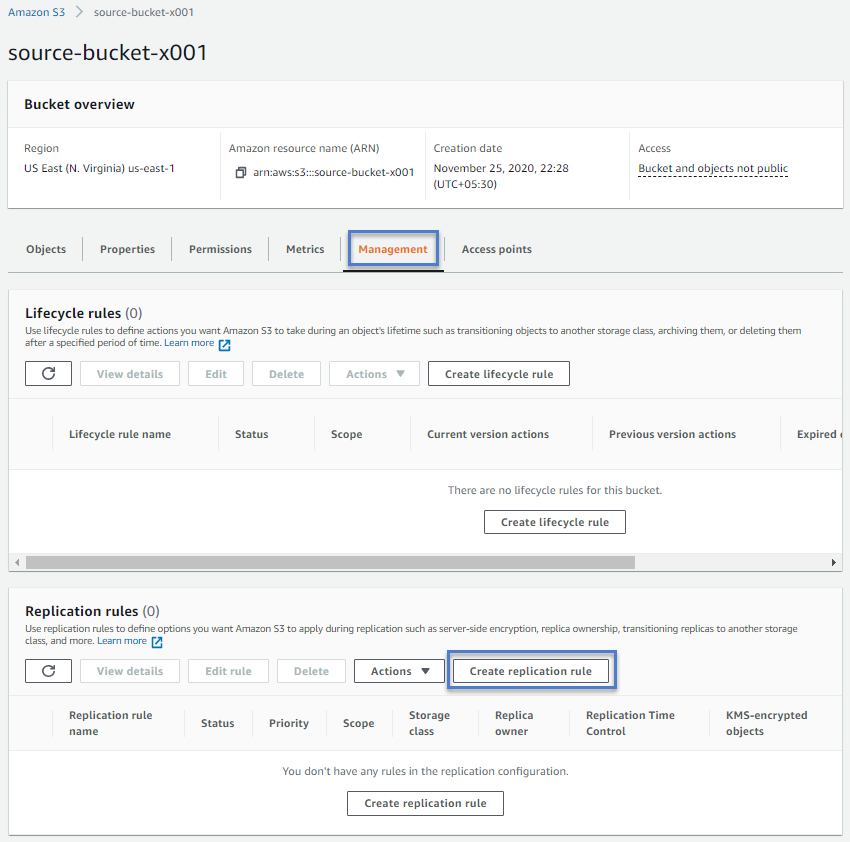
- Click on the Management tab under bucket details.
- And scroll down to the Replication rules section.
- Click on the Create replication rule button.
Make sure you have versioning enabled on both source and destination buckets, or else you will see a warning like the one below –


In replication rule configuration wizard –

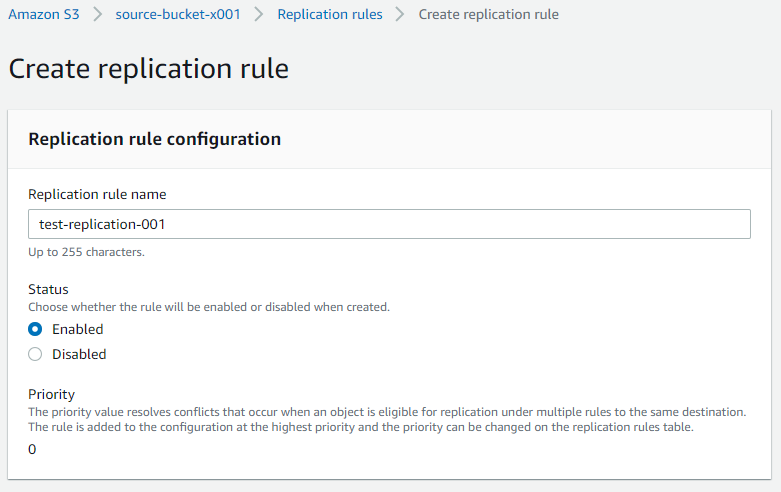
- Replication rule configuration
- Replication rule name: Name
- Status: Enable/disable the rule on creation
- Priority: In the case of multiple replication rules, the object follows priority.

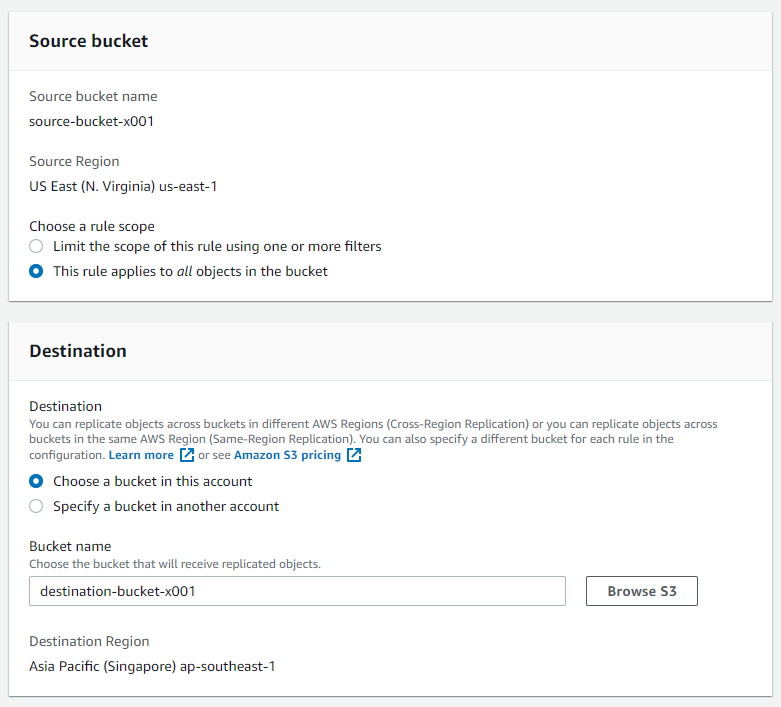
- Source bucket
- Source bucket name: Prepopulated.
- Source region: Region of source bucket. Prepopulated.
- Choose a rule scope: Replication can be limited to selected objects by using a prefix filter. Or apply it for all objects in the bucket.
- Destination
- Bucket name: Choose bucket from the same account or a different account here as a destination.
- Destination Region: Region of destination bucket.

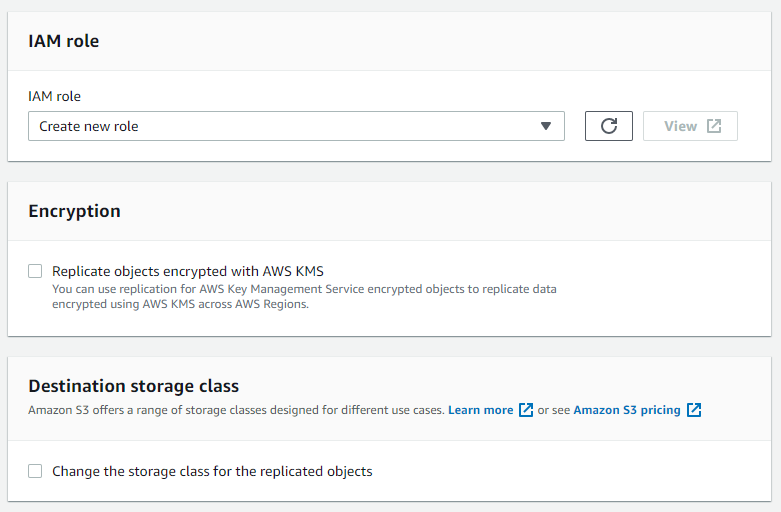
- IAM role
- Select the IAM role to be used by S3 for performing the copy operation. Make sure you have carefully added proper permissions to it. I choose to create new for this exercise.
- Encryption
- If data is encrypted using AWS KMS, it can be replicated.
- Destination storage class
- Change the storage class of replicated objects or keep it the same as the source.

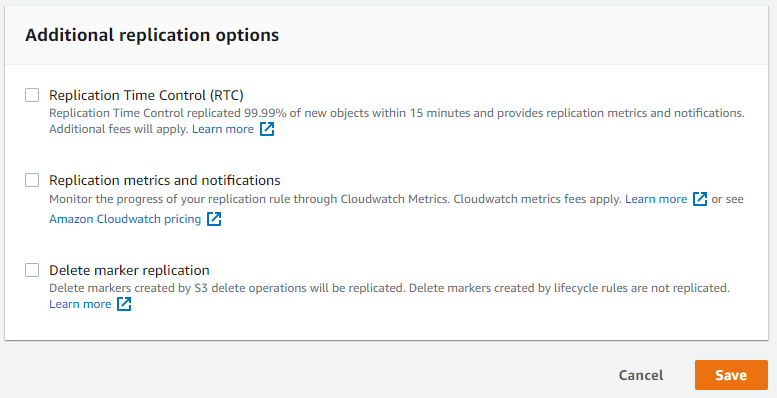
- Additional replication options
- RTC: Premium service with guaranteed 15 mins ETA for replication of new objects
- Replication metrics and notifications: Cloudwatch for replication!
- Delete marker replication: Enable to replicate S3 delete operation created delete markers. Remember lifecycle rule created delete markers can not be replicated.
Click the Save button. Replication rule should be created and you should be presented with rule details like below –

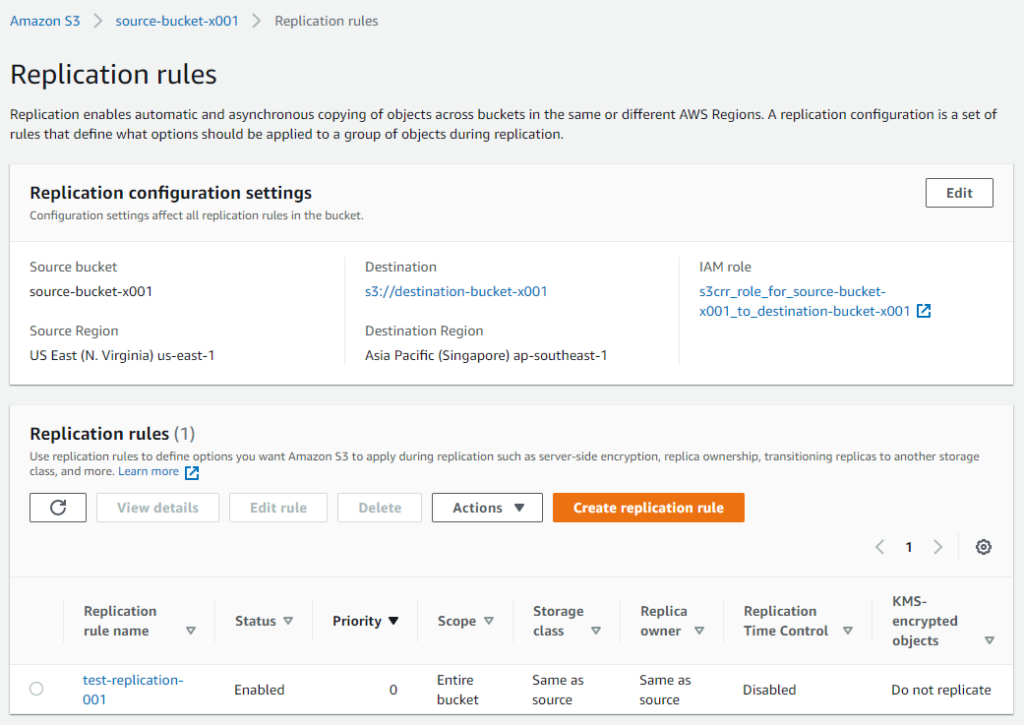
You can even see the IAM role created by AWS while creating a rule since we opt to create one.
Now, it’s time for the test. I had one file already in the source bucket, and it’s not replicated after creating the rule since it’s only applied to new objects uploaded to the source bucket after rule creation.

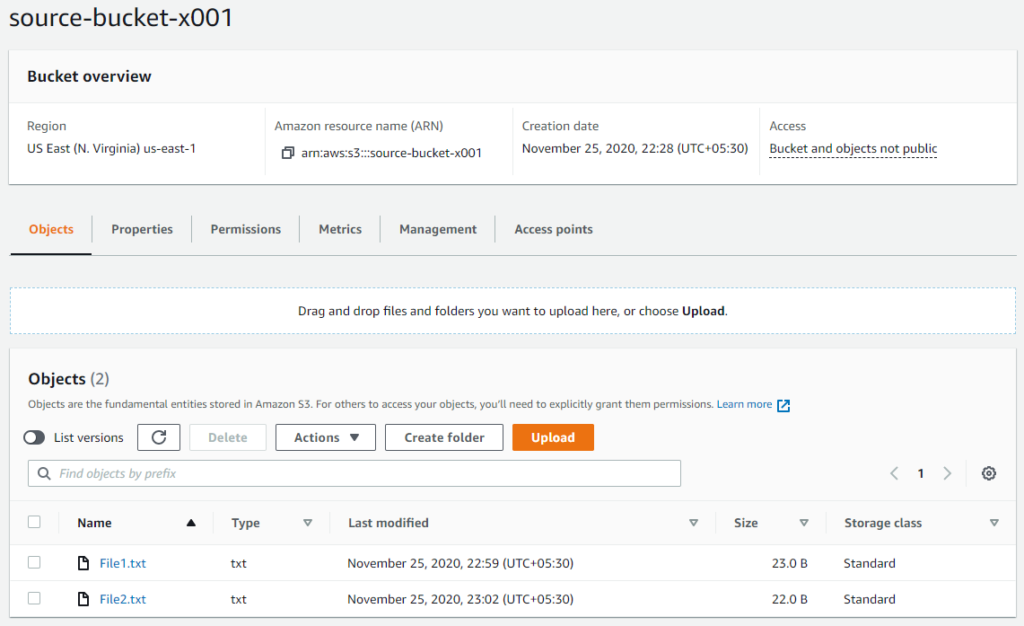
File1.text was existing before rule creation and File2.txt uploaded after rule creation. So the destination bucket should be having File2.txt replicated from the source bucket.
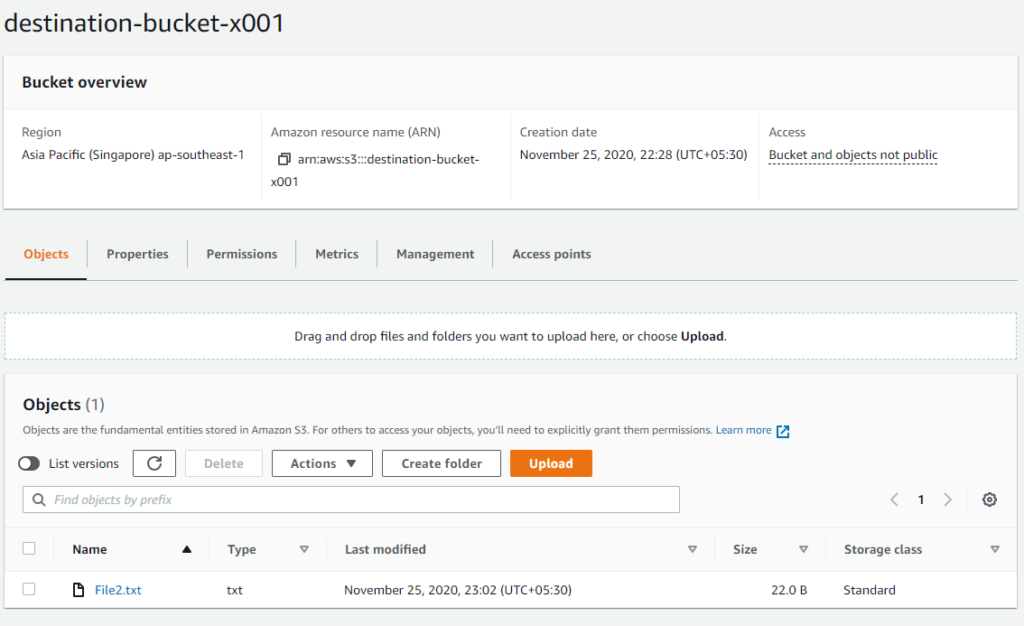
And its there! So replication rule worked perfectly!
How to check if object is replicated?
To verify if the object is replicated or not. Click on the object and check its replication status.

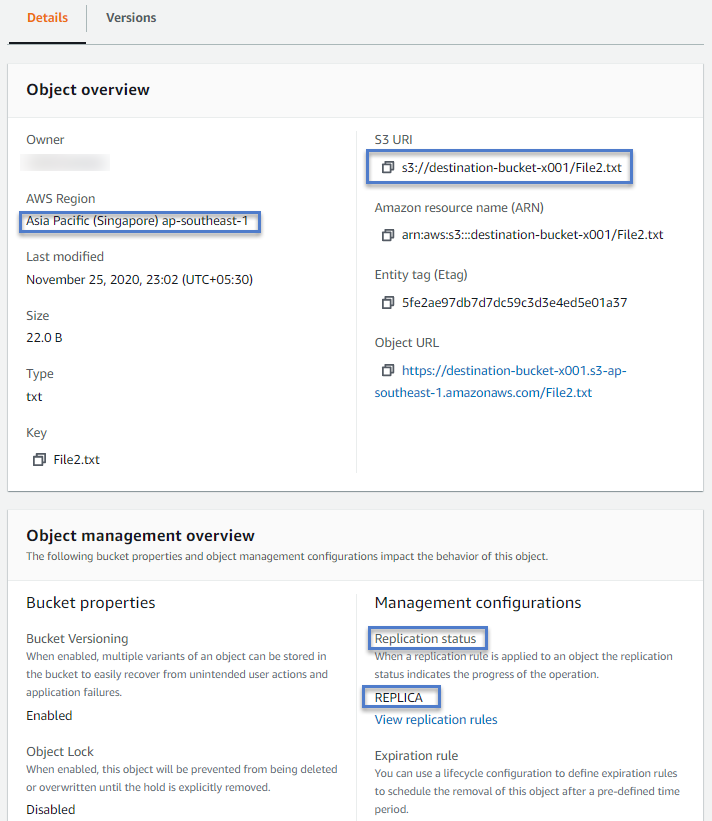
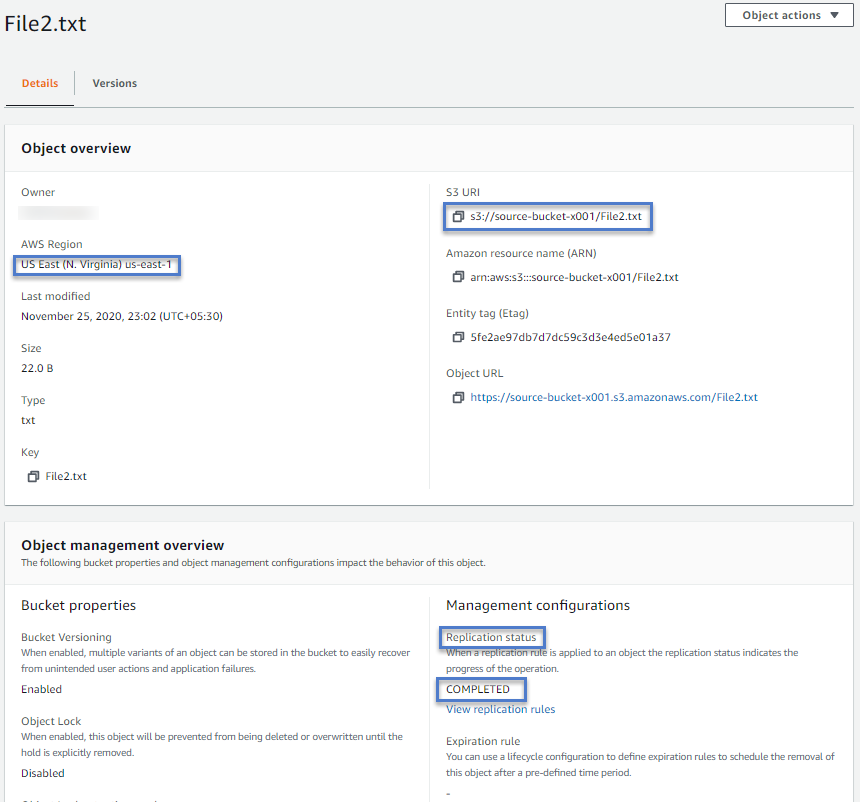
For replicated object replication status should show it as REPLICA. Whereas, for source object i.e., who uploaded to source object and then got replicated status is COMPLETED

And it would be blank for non-replicated objects. Since File1.txt was uploaded before replication rule creation, the rule was not applied to it.

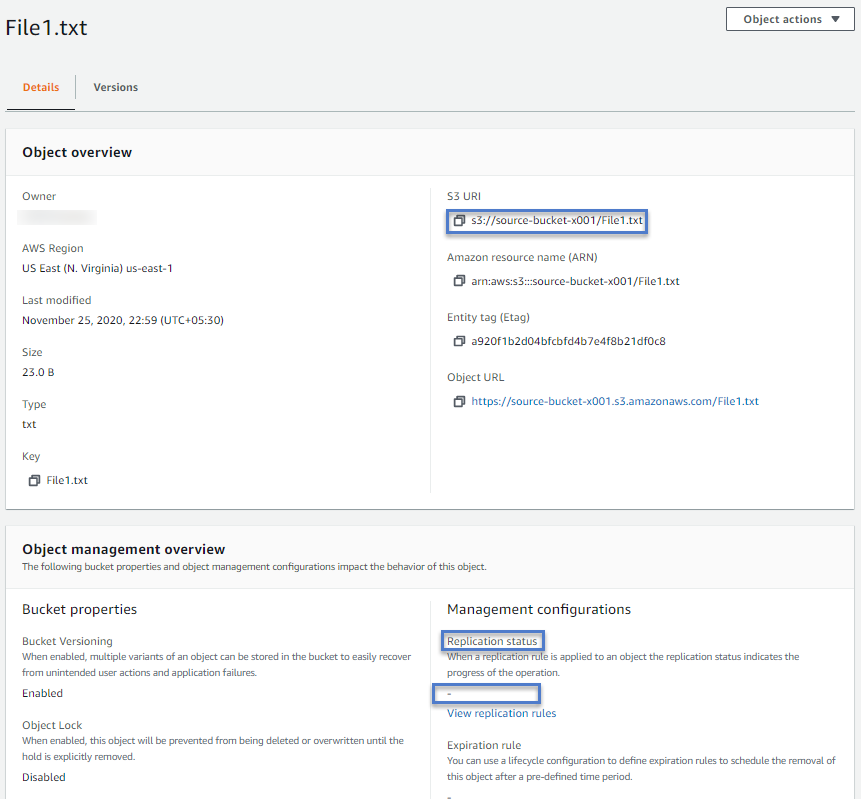
And hence we see its replication status as - i.e., no replication rules applied to this object.