This post details my side project—a one-page resume website that I constructed without incurring any expenses.


What is one-page resume website?
A one-page resume website serves as a digital manifestation of your resume, offering a modern alternative to the traditional paper-based format. While PDF resumes remain effective for email sharing, the dynamic nature of resume websites provides an excellent digital representation of your profile. Particularly advantageous in fields like digital, marketing, and art, a resume website becomes an ideal platform to showcase portfolios, offering a level of presentation that is challenging to achieve with traditional paper or PDF formats.
I created my one-page resume website as a side project. And when it’s budget-friendly, why not!
We are talking about: https://resume.kerneltalks.com
The frontend
The one-page resume website is static, meaning its content doesn’t change frequently. Being a single-page site eliminates the need for a content management system, making a basic HTML website the ideal choice – especially if you’re not into web design and don’t have a substantial budget or time commitment.
Since web design isn’t my expertise, I opted for an HTML template as a foundation. If you know HTML, customizing the template with your data is a straightforward task, and your site is ready to be hosted.
I chose a free HTML template, so there’s zero investment made. It’s essential to respect the personal use terms specified by the template providers and include a link back to them on your website.
The backend
Given that it’s a one-page static HTML website, it makes sense to minimize hosting expenses (in terms of money and time). Amazon S3 website hosting seems to be the optimal choice. Uploading files to an S3 bucket, configuring a few settings, and your website is live! You can find the complete procedure here.
Since it’s a single HTML page, my website’s size is a mere 4MB, resulting in negligible (I would say zero) S3 storage charges.
Amazon S3 website hosting provides an AWS-branded HTTP endpoint. If you desire a custom domain or HTTPS protocol, integrating CloudFront with S3 is the solution.
I utilized a subdomain on my existing registered domain and set up a CNAME entry for it against CloudFront’s DNS.
If you don’t have a domain, expect a registration investment of around ~$13 per year. In my case, it was zero. Additionally, CloudFront bills based on the number of requests, so your costs will depend on your website’s traffic. Considering the nature of a personal resume website, significant traffic, and associated costs are negligible.
For HTTPS, you can create a free SSL certificate in Amazon Certificate Manager and use it with the CloudFront distribution.
The result
The outcome is a serverless, responsive, compact, HTML-based, secure, static, one-page resume website, leveraging the top-tier CDN, Amazon CloudFront, all achieved with no upfront investment!

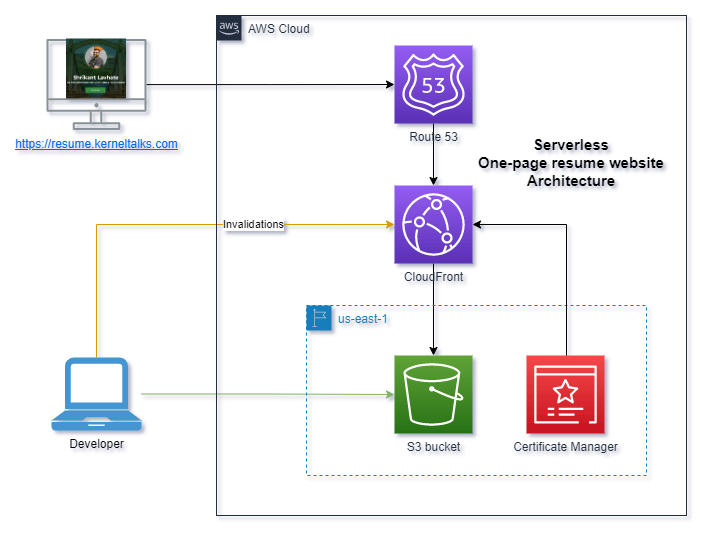
You could make it more secure by adding a WAF (Web Application Firewall) on top of CloudFront though. Since it was a zero dollar project, WAF was not included in the design at that time.