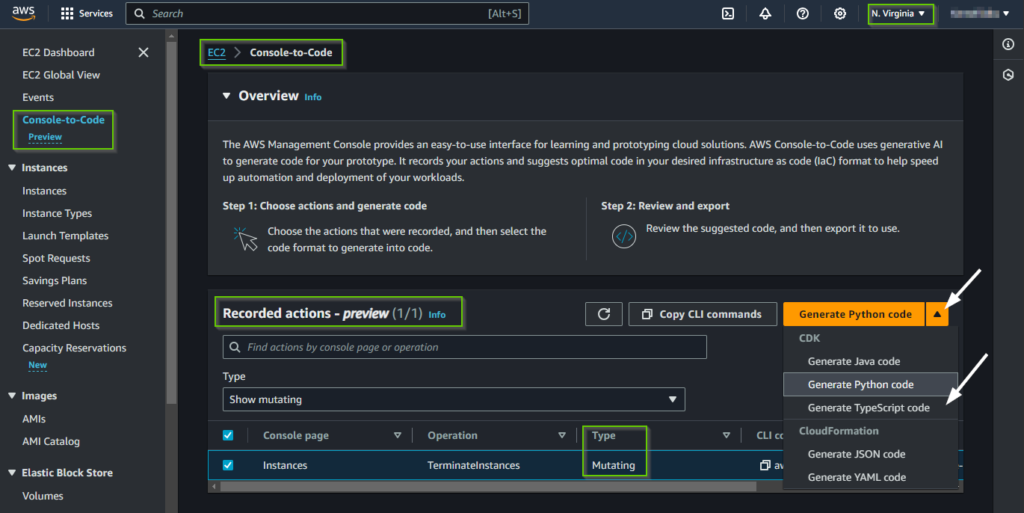
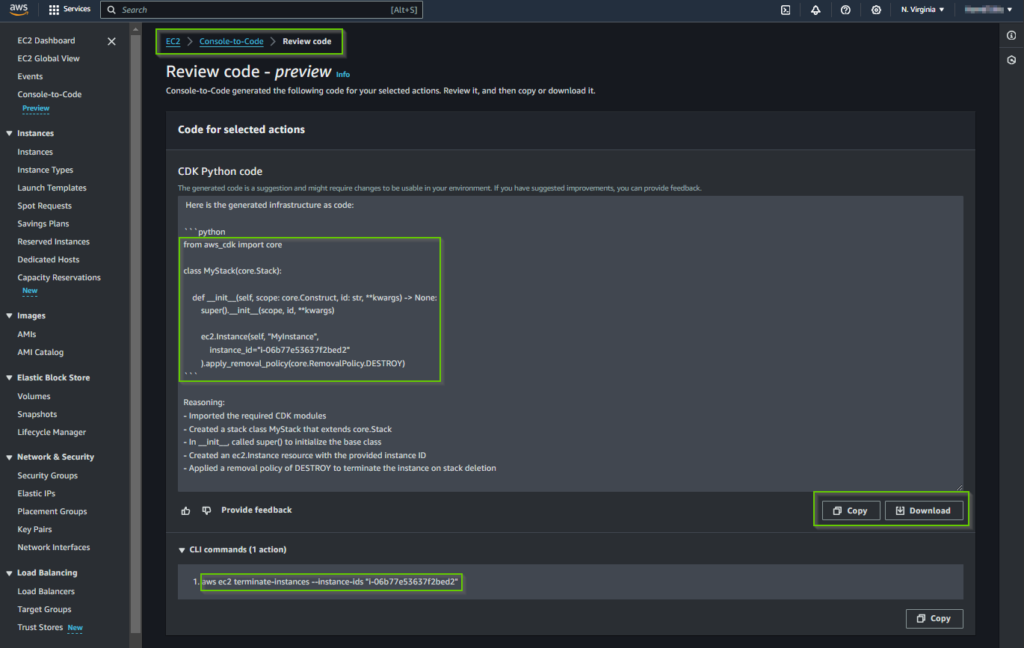
AWS has recently introduced a Console-to-Code functionality, allowing users to automatically generate Infrastructure as Code (IaC) templates based on actions performed in the EC2 console. Additionally, AWS offers the CloudFormation IaC Generator, a compact tool embedded in the AWS CloudFormation console. This tool facilitates the creation of CloudFormation templates for pre-existing resources within your account. In the following post, we will walk through this tool and step-by-step instructions on how to use it.


What is the IaC generator?
The AWS CloudFormation IaC generator lets you generate a template for AWS resources that are already provisioned in your account and not being managed by CloudFormation. It does makes sense to exclude resources managed by CloudFormation since you already have a template for them!
Firstly, initiate a scan of your account under the IaC generator console to provide the tool with a comprehensive list of resources not governed by CloudFormation. There are a few quota limits on these scans which can be referred here.
Upon completion of the scan, the tool displays a list of resources that are not under CloudFormation management. Begin creating the template by selecting these resources, and the tool will then generate the template in either YAML or JSON format.
The powerful IaC generator capabilities of CloudFormation can also be accessed via the AWS CLI, making it a compelling choice for streamlined and efficient automation.
How to use the IaC generator?
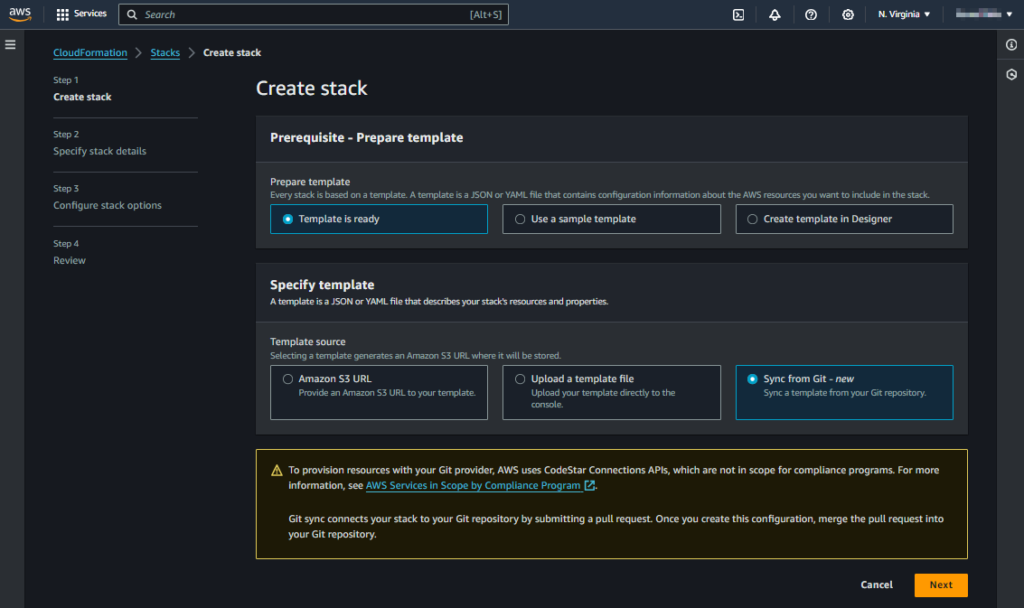
- Login to Cloudformation console.
- Click on IaC generator link on the left hand side menu.

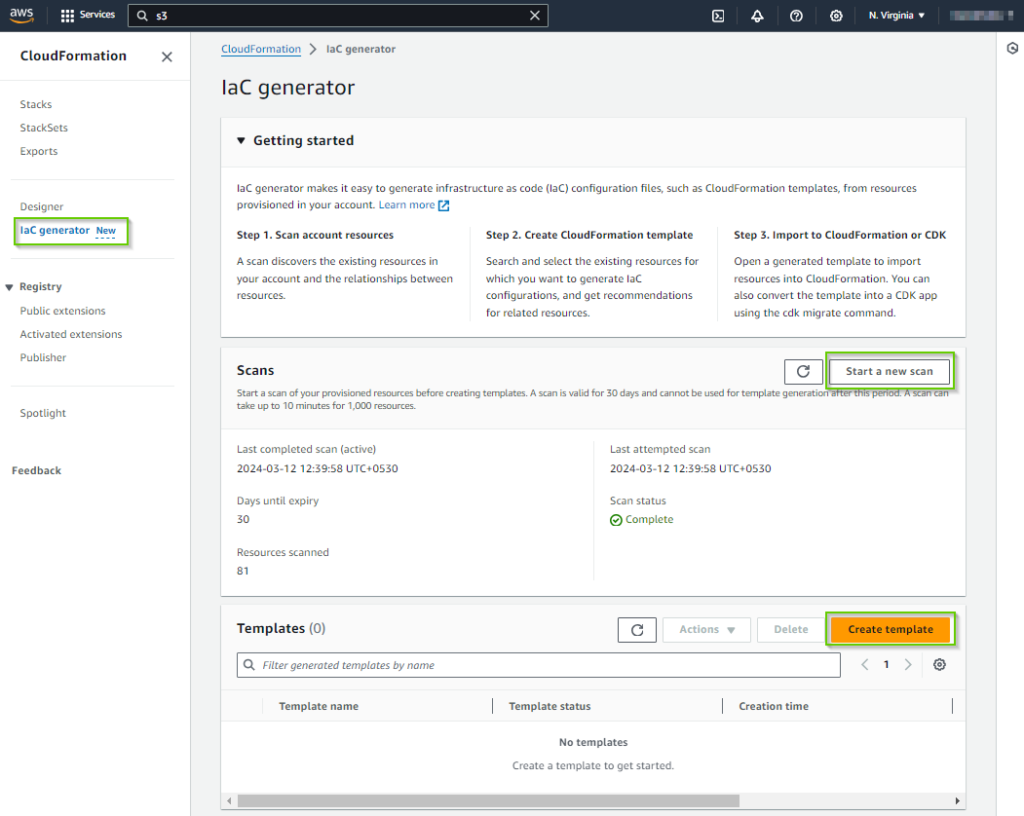
- If you are using it for the first time, you might want to hit the Start a new scan button for running the first resources scan of this tool. This scan will identify all the AWS resources in your account that are not managed by CloudFormation.
- Click on Create template button.
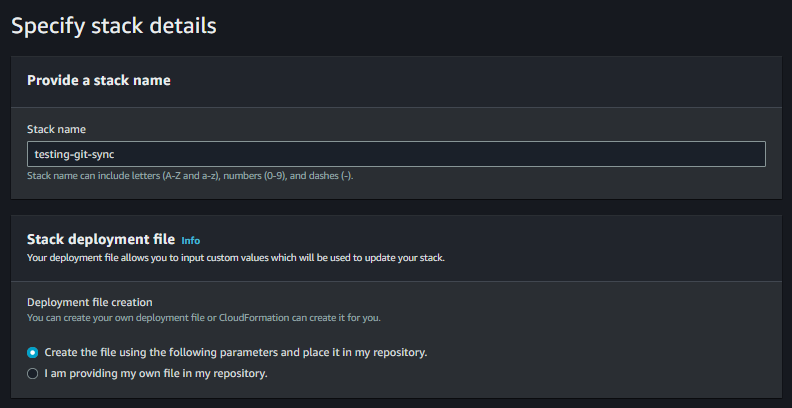
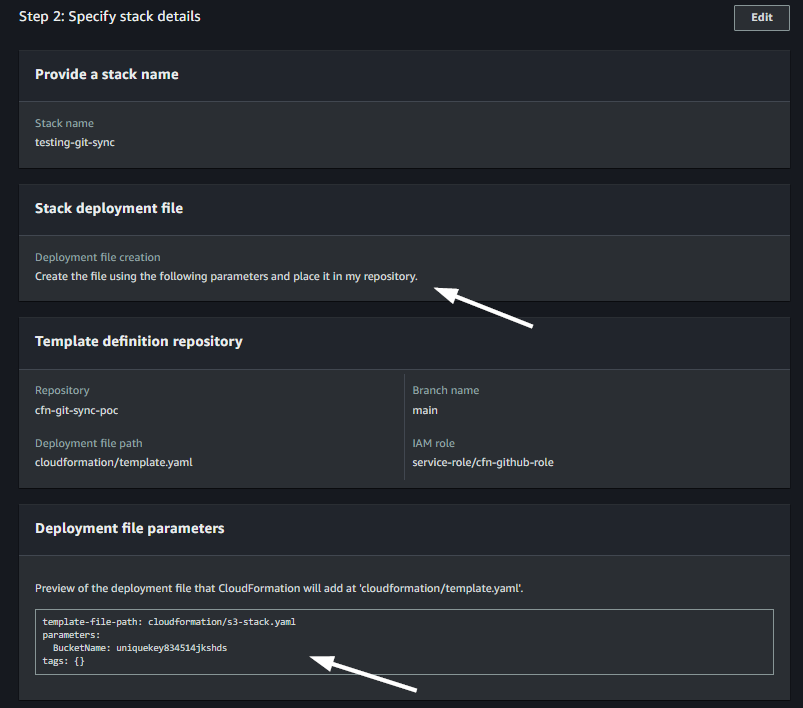
- On a create wizard, provide the template details.

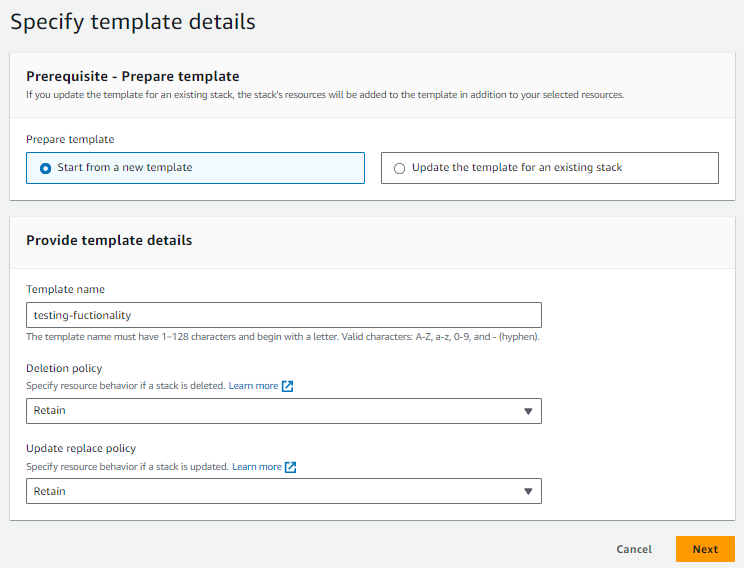
- We are choosing to create a template from scratch. If you want to add a resource in exsiting CloudFormation stack then choose ‘Upadte the template for an existing stack‘. Make an appropriate choice for deletion and update replace policies.
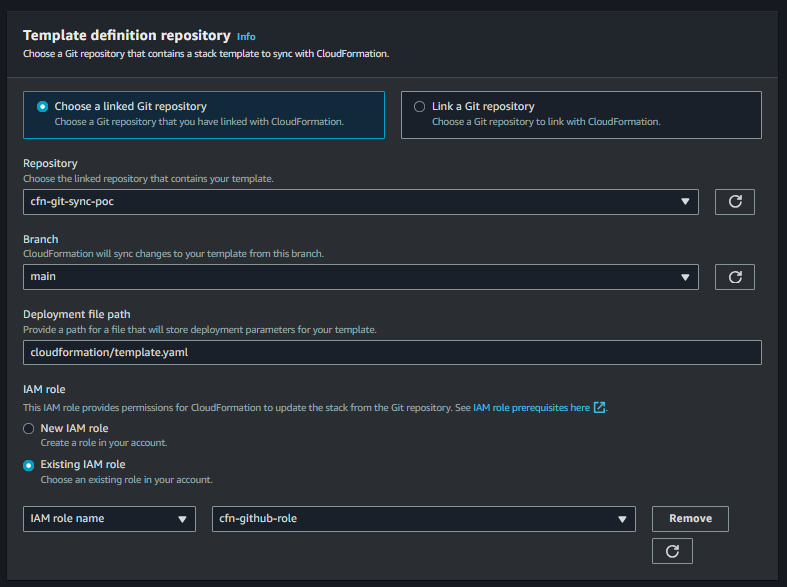
- On a next screen, choose resources to be included in the IaC template.

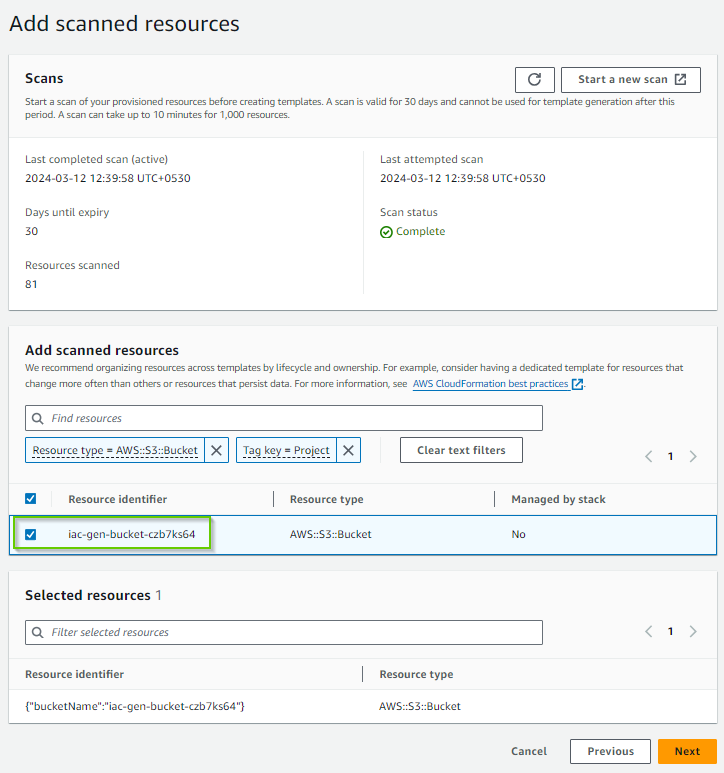
- If the resource you are looking for is not in the list, probably you need to initiate the new scan since your scan inventory might be the old one.
- Click on Next button and choose related resources if any.

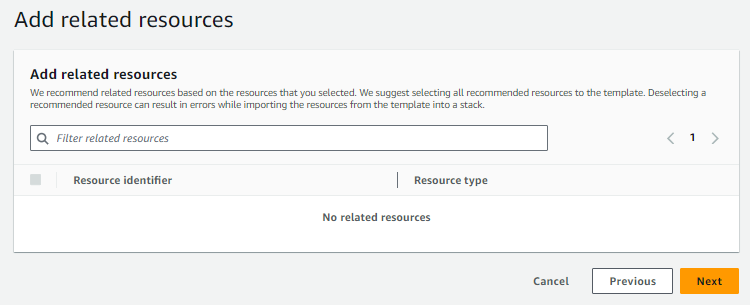
- The tool gathers the list of dependent or related resources from the resource you chose in the last step. Since we selected S3 bucket with no external dependency like KMS key, etc. we are not having any related resource.
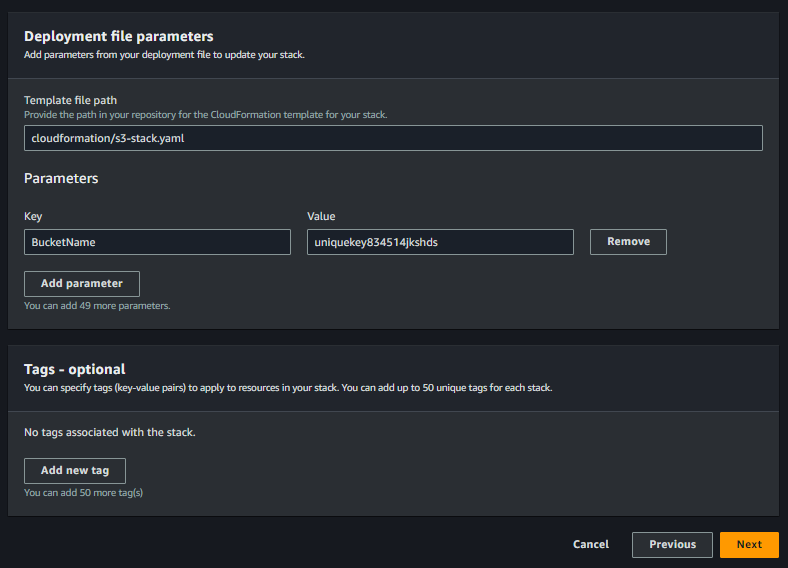
- Click on Next button for the final Review screen of the wizard.

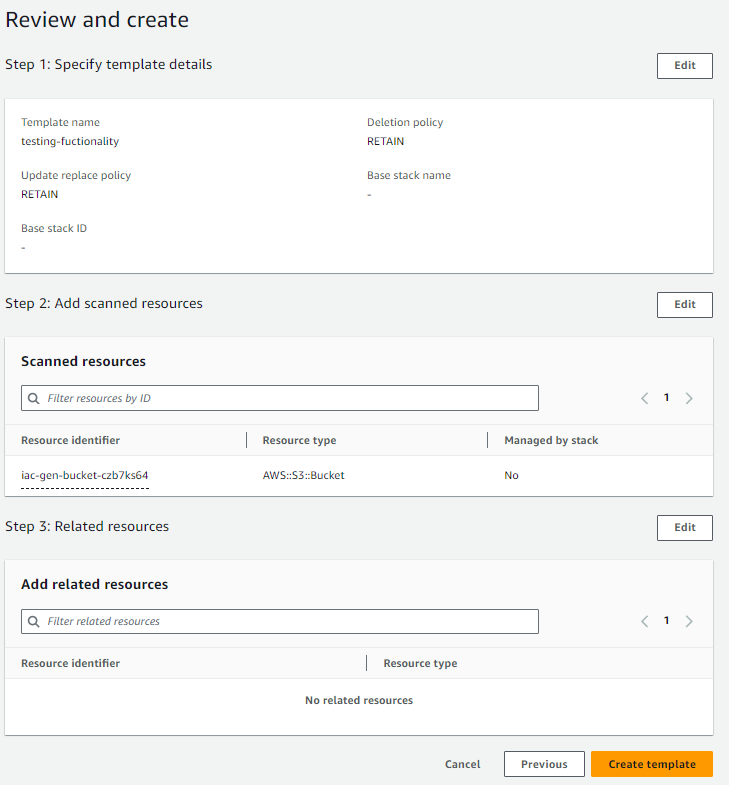
- Review the selections and click Create template button.

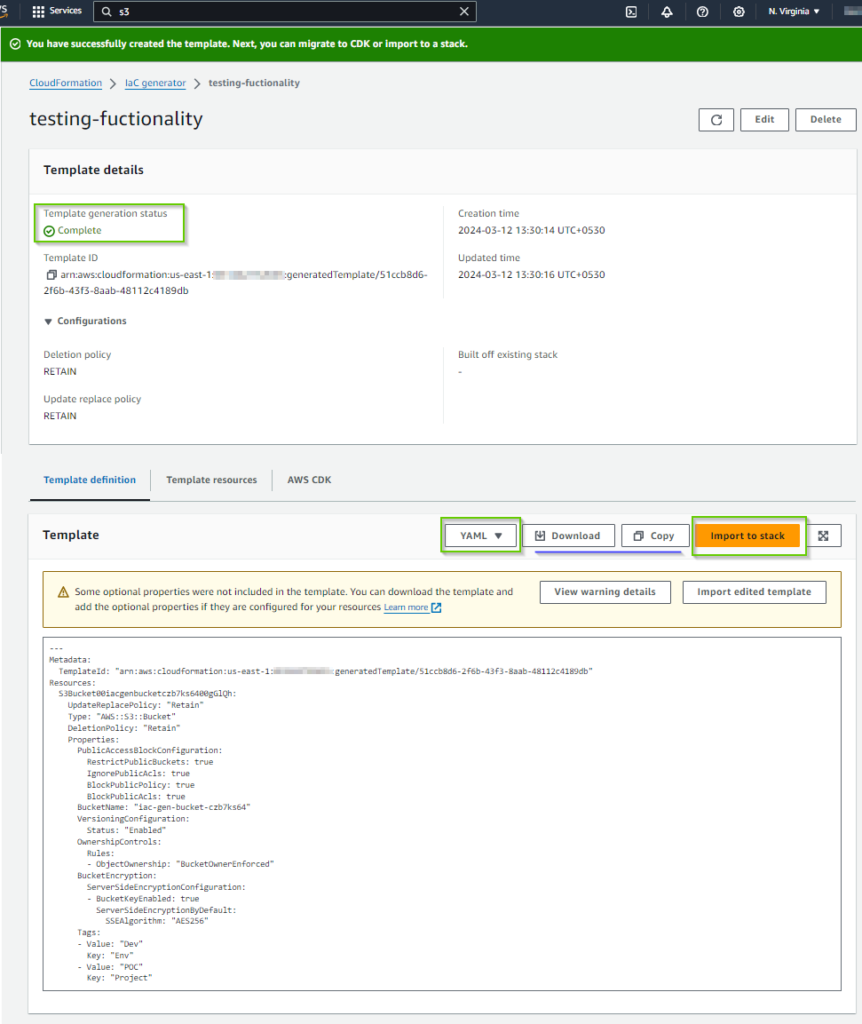
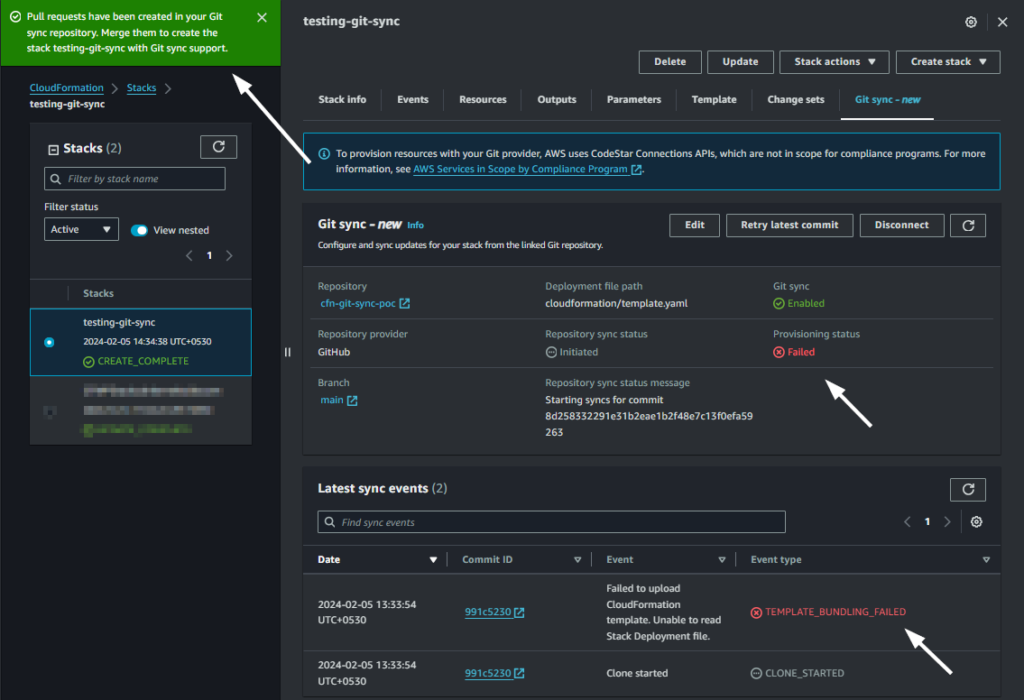
- The teamplate will be genrated. You will have option to choose YAML or JSON format. You can copy or download it as well. Or you can import it into a CloudFormation Stack by clicking Import to stack button.
- There is also AWS CDK application command in last tab AWS CDK
Importing the AWS resources in to the CloudFormation stack
It is always advisable to manage AWS resources through IaC templates, as this approach enhance resource management and minimizes the cloud clutter. One common challenge in the IaC journey is incorporating manually created existing resources into IaC. The IaC generator proves valuable in this scenario by assisting in the creation of IaC templates for your resources, facilitating a seamless transition.
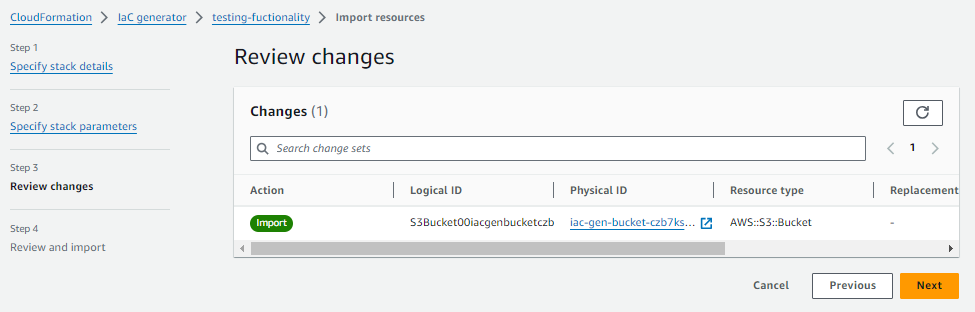
Using IaC generator, you can generate the IaC template of existing resources that are not managed by Cloudformation. Once the template is generated, it also offers an option to import it in to the stack. Select that option (the last screesnhot in above section) and it will kickstart Cloudfomation import stack wizard.
Review all the information on the console, and then proceed to initiate the creation of a new stack that will import the chosen resources. I won’t go into a detailed, step-by-step procedure here, as it follows the standard CloudFormation stack process.

The CloudFormation stack will be created and you can see the selected resource is now imported and managed by CloudFormation.

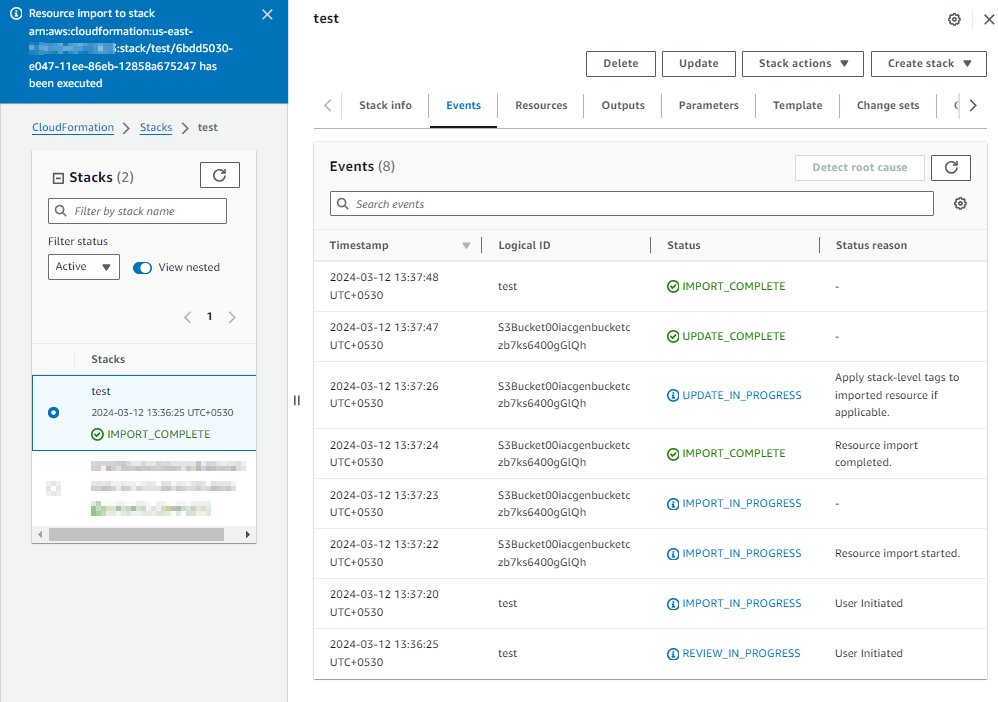
This is a convenient method to scan for resources not governed by CloudFormation and subsequently import them into a CloudFormation stack, thereby fostering the adoption of Infrastructure as Code practices within your account and organization.
Conclusion
The IaC generator from AWS is a commendable initiative aimed at assisting customers in achieving 100% compliance with Infrastructure as Code for their infrastructure. It provides a seamless experience, effortlessly identifying non-IaC resources and smoothly importing them into CloudFormation stacks. Furthermore, it expedites the adoption of IaC by automatically generating code templates for you.