Step by step rundown to troubleshoot AWS cross-account assume role issues.
Cross-account Assume role
AWS cross-account role access is one of the most common use cases in cloud environments and is always a headache to troubleshoot if one is not familiar enough with IAM. In this article, we will walk you through step by step procedure to drill down into the root cause of why AWS cross-account IAM role access is not working.
Typically, you will be seeing error messages like –
An error occurred (AccessDeniedException) when calling the xxx operation: User: arn:x....x is not authorized to perform xxx:xxx on resource arn:x....x because no resource-based policy allows the xxx:xxx action.
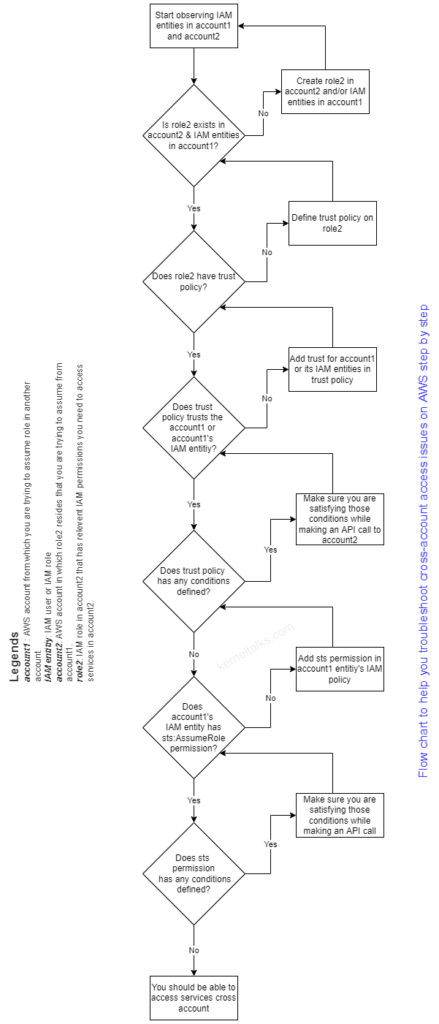
Let’s formalise the legends for a better understanding of the below steps:
account1 is the account from which role assume request is initiated
account2 is the account in which target role2 exists and IAM entity from account1 is trying to assume it.
IAM entity from account1 can be IAM user or role.
Consider below steps/points that will help you troubleshoot cross-account access issues.
account1 IAM entity (user/role)should have permission sts:AssumeRole defined in IAM policy attached to it. If it has some condition attached to it, those conditions must be satisfied in the assume call.
account2‘s IAM role role2 should have trust policy defined. This trust policy should trusts (principal field) the account1 or account1‘s IAM entity (user/role) which is initiating the assume call.
If trust policy is having condition defined (condition field), then assume call should be satisfying those conditions.
account2‘s IAM role must have permissions properly defined that account1’s IAM entity want to use in account2.
Or you can go through the below flow chart and drill down to the root cause of your problem!
A list of tools/configurations to make sysadmin life easy on Windows workstation!
Linux lovers on Windows!
This article is intended for the sysadmins who use Windows workstations for their job and yet would love to have Linux experience on it. Moreover, if they are interacting with AWS CLI, GIT, etc. CLI based tools on daily basis then its best suited for them. I list all the tools and their respective configurations you must have in your arsenal to make your journey peaceful, less frustrating and avoid non-Linux workstation issues. I expect the audience to be comfortable with Linux.
Without further a due let’s get started.
Windows Subsystem for Linux
First of all, let’s get Linux on the Windows 🙂 WSL is a Windows feature available from Windows 10 (WSL Install steps). Install the latest (at the time of this article draft) Ubuntu 20.04 LTS from Microsoft Store. Post-installation you can run it just like other Windows apps. For the first login, you will be prompted to set a username and password. This user is configured to switch to root using sudo.
Now, you have a Linux subsystem running on your Windows! Let’s move on to configure it to ease up daily activities.
Install necessary packages using apt-get. I am listing here frequently useful for your quick reference –
I even configured WSL normal user to perform passwordless sudo into root at the login to save the hassle of typing command and password to switch into root. I love to work at root # prompt!
Avoid sound beeps from Linux terminal
With WSL, one thing you might like to avoid is workstation speaker beeps/bells due to the Linux terminal prompt of vi editors. Here is how you can avoid them :
# echo set bell-style none >>/etc/inputrc # Stops prompt bells
# echo set visualbell >> ~/.vimrc # Stops vi bells
Setting up Git on WSL
Personal Authentication Token (PAT) or SSH keys can be leveraged for configuring Git on WSL. I prefer to use SSH keys so listing steps here –
Create and add SSH keys to GitHub account. Steps here.
Authorize the organizations for the Public key you are uploading to Git by visiting Key settings on Git.
Add ssh-agent service startup and key identity addition at login under user/shell profile. Dirty way to do it on bash is adding below lines in ~/.bashrc file.
Add alias to your Git folder on Windows drive so that you can navigate to it quickly when running all Git commands like repo clone. It can be done by adding below command to your user/shell profiles. You can choose alias (gitdir) of your owne choice and the destination cd <path> too.
alias gitdir='cd /mnt/c/Users/<username>/Downloads/Github'
Setting up prompt to show current Git branch
It’s easy. You need to tweak your prompt PS1 with git branch command output!
The git branch output looks like this –
# git branch
* master
With help of sed you can take out branch name from it. Obviously, you also want to redirect error (on non-git directory command will fail). And add brackets around branch name to have the same look like gitbash prompt. That sums up to below code –
Add this to a function and call this function in your PS1! Ta da. Sample prompt with colours from Ubuntu. Don’t forget to set this into shell profile (e.g. ~/.bashrc) so that it will be loaded on your login.
Oh yes, even sysadmins code for their automation stuff and with IaC being hot in the market it’s essential for sysadmins to code as well. Since we discussed this article is intended for Windows users, Microsoft Visual Code is an undefeated entry here! Its superb code editing tool with numerous plugins makes you comfortable to code.
Tweaking Visual code for PuTTY like experience
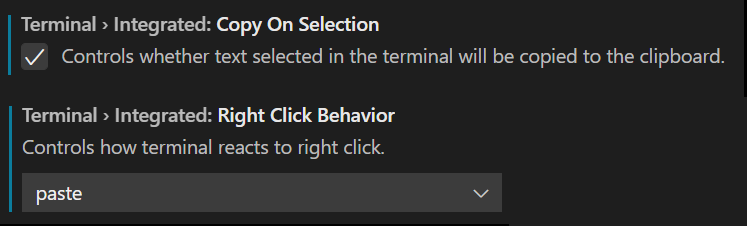
PuTTY is the preferred tool for SSHing in Linux world. The beauty of PuTTY lies in its copy-paste capabilities. The same capabilities can be configured on MS Visual code terminal.
Head to the terminal settings by entering the command Terminal: configure Terminal Settings in the command palette (ctrl + shift + p). On the setting screen set below options –
MS VS code setting for Putty copy-paster behaviour!
Setting up VS Code to launch from WSL
Since we already configured Git on WSL, it makes sense to directly run code . command in WSL from Git Directory and have VS code started on the Windows workstation. For that, you just need to add the alias of the code.exe file with an absolute path on Windows to code command!
If you have installed VS code with default config then the below command in your user/shell profile should do the trick.
alias code='/mnt/c/Users/<username>/AppData/Local/Programs/Microsoft\ VS\ Code/code.exe'
Code linters
There are two ways you can have your code linted locally before you commit it on Git.
Install respective code linter binaries/packages on WSL. Its Linux!
Install code linters on VS code if appropriate plugin is available.
Running docker on WSL without installing Docker Desktop for Windows
With WSL version 2, one can run docker on WSL without installing the docker desktop for windows. The Docker installation remains the same inside WSL just like any other Linux installation.
Once installed make sure you are running on WSL version 2. If not upgrade to WSL 2.
Convert the current WSL distro to make use of WSL 2 using the command in PowerShell –
A quick rundown on how to install Cluster Autoscaler on AWS EKS.
CA on EKS!
What is Cluster Autoscaler (CA)
Cluster Autoscaler is not a new word in the Kubernetes world. It’s a program that scales out or scales in the Kubernetes cluster as per capacity demands. It is available on Github here.
For scale-out action, it looks for any unschedulable pods in the cluster and scale-out to make sure they can be scheduled. If CA is running with default settings, then it checks every 10 seconds. So basically it detects and acts for scale-out in 10 secs.
For scale in action it watches nodes for their utilization and any underutilized node will be elected for scale in. The elected node will have to remain in an un-needed state for 10 minutes for CA to terminate it.
CA on AWS EKS
As you know now, CA’s core functionality is spawning new nodes or terminating the un-needed ones, it’s essential it must be having underlying infrastructure access to perform these actions.
In AWS EKS, Kubernetes nodes are EC2 or FARGATE compute. Hence, Cluster Autoscaler running on EKS clusters should be having access to respective service APIs to perform scale out and scale in. It can be achieved by creating an IAM role with appropriate IAM policies attached to it.
Cluster Autoscaler should be running in a separate namespace (kube-system by default) on the same EKS cluster as a Kubernetes deployment. Let’s look at the installation
How to install Cluster Autoscaler on AWS EKS
Creating IAM role
IAM role of Autoscaler needs to have an IAM policy attached to it with the below permissions –
You will need to use this policy ARN in eksctl command. Also, make sure you have an IAM OIDC provider associated with your EKS cluster. Read more in detail here.
As mentioned above, we need to have an IAM role in a place that can be leveraged by Cluster Autoscaler to perform resource creation or termination on AWS services like EC2. It can be done manually, but it’s recommended to perform it using eksctl command for its comfort and perfection! It takes care of trust relationship policy and related conditions while setting up a role. If you do not prefer eksctl then refer to this document to create it using AWS CLI or console.
You need to run it from the terminal where AWS CLI is configured.
NAMESPACE: ns under which you plan to run CA. Preference: kube-system
CLUSTER-REGION: Region in which EKS Cluster is running
MANAGED-POLICY-ARN: IAM policy ARN created for this role
# eksctl create iamserviceaccount --cluster=blog-cluster --namespace=kube-system --name=cluster-autoscaler --attach-policy-arn=arn:aws:iam::xxxxxxxxxx:policy/blog-eks-policy --override-existing-serviceaccounts --region=us-east-1 --approve
2022-01-26 13:45:11 [ℹ] eksctl version 0.80.0
2022-01-26 13:45:11 [ℹ] using region us-east-1
2022-01-26 13:45:13 [ℹ] 1 iamserviceaccount (kube-system/cluster-autoscaler) was included (based on the include/exclude rules)
2022-01-26 13:45:13 [!] metadata of serviceaccounts that exist in Kubernetes will be updated, as --override-existing-serviceaccounts was set
2022-01-26 13:45:13 [ℹ] 1 task: {
2 sequential sub-tasks: {
create IAM role for serviceaccount "kube-system/cluster-autoscaler",
create serviceaccount "kube-system/cluster-autoscaler",
} }2022-01-26 13:45:13 [ℹ] building iamserviceaccount stack "eksctl-blog-cluster-addon-iamserviceaccount-kube-system-cluster-autoscaler"
2022-01-26 13:45:14 [ℹ] deploying stack "eksctl-blog-cluster-addon-iamserviceaccount-kube-system-cluster-autoscaler"
2022-01-26 13:45:14 [ℹ] waiting for CloudFormation stack "eksctl-blog-cluster-addon-iamserviceaccount-kube-system-cluster-autoscaler"
2022-01-26 13:45:33 [ℹ] waiting for CloudFormation stack "eksctl-blog-cluster-addon-iamserviceaccount-kube-system-cluster-autoscaler"
2022-01-26 13:45:50 [ℹ] waiting for CloudFormation stack "eksctl-blog-cluster-addon-iamserviceaccount-kube-system-cluster-autoscaler"
2022-01-26 13:45:52 [ℹ] created serviceaccount "kube-system/cluster-autoscaler"
The above command prepares the JSON CloudFormation template and deploys it in the same region. You can visit the CloudFormation console and check it.
Installation
If you choose to run CA in different namespace by defining custom namespace in manifest file, then replace kube-system with appropriate namespace name in all below commands.
Download and prepare your Kubernetes to manifest file.
Apply the manifest to your EKS cluster. Make sure you have the proper context set for your kubectl command so that kubectl is targeted to the expected EKS cluster.
# kubectl apply -f cluster-autoscaler-autodiscover.yaml
serviceaccount/cluster-autoscaler configured
clusterrole.rbac.authorization.k8s.io/cluster-autoscaler created
role.rbac.authorization.k8s.io/cluster-autoscaler created
clusterrolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
rolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
deployment.apps/cluster-autoscaler created
Add annotation to cluster-autoscaler service account with ARN of the IAM role we created in the first step. Replace ROLE-ARN with IAM role arn.
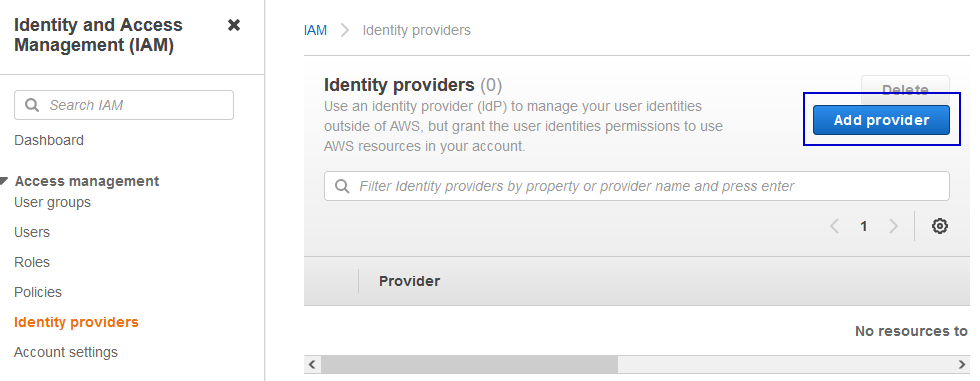
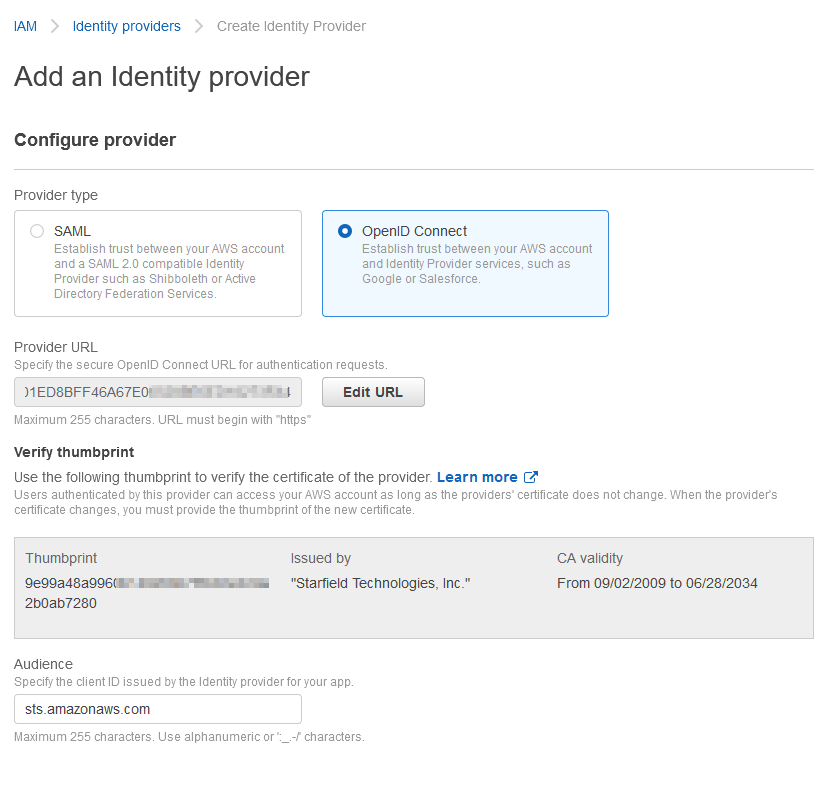
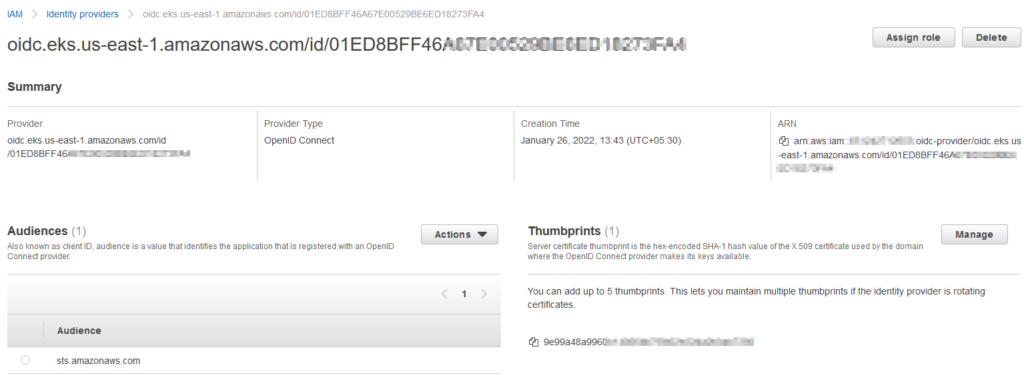
We will be creating OpenID Connect Identity Provider for the AWS EKS cluster in the IAM service. It will enable to establish trust between AWS account and Kubernetes running on EKS. For using IAM roles with service accounts created under the EKS cluster, it must have the OIDC provider associated with the cluster. Hence, it’s important to have this created at the beginning of the project along with the cluster.
Let’s get into steps to create an OIDC provider for your cluster.
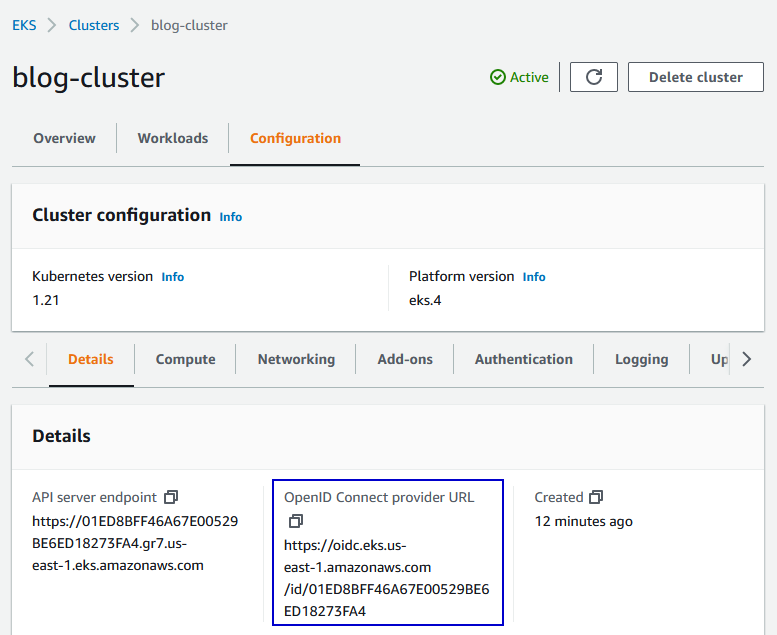
First, you need to get the OpenID Connect provider URL from EKS Cluster.
Steps to configure CLI for running kubectl commands on EKS clusters.
kubectl with EKS!
kubectl is the command-line utility used to interact with Kubernetes clusters. AWS EKS is AWS managed Kubernetes service broadly used for running Kubernetes workloads on AWS Cloud. We will be going through steps to set up the kubectl command to run with the AWS EKS cluster. Without further due, let’s get into it.
AWS CLI configuration
Install AWS CLI on your workstation and configure it by running –
# aws configure
AWS Access Key ID [None]: AKIAQX3SNXXXXXUVQ
AWS Secret Access Key [None]: tzS/a1sMDxxxxxxxxxxxxxxxxxxxxxx/D
Default region name [us-west-2]: us-east-1
Default output format [json]: json
# aws eks --region us-east-1 update-kubeconfig --name blog-cluster
Added new context arn:aws:eks:us-east-1:xxxxxxxxxx:cluster/blog-cluster to C:\Users\linux\.kube\config
At this point your kubeconfig point to the cluster of your interest. You can execute kubectl commands and those will be executed against the cluster you mentioned above.
# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-66cb55d4f4-hk9p5 0/1 Pending 0 6m54s
kube-system coredns-66cb55d4f4-wmtvf 0/1 Pending 0 6m54s
I did not add any nodes yet to my EKS cluster hence you can see pods are in a pending state.
If you have multiple clusters configured in kubeconfig then you must switch context to interested cluster before running kubectl commands. To switch context –
# kubectl config use-context <CONTEXT-NAME>
# kubectl config use-context arn:aws:eks:us-east-1:xxxxxxxxxx:cluster/blog-cluster
Switched to context "arn:aws:eks:us-east-1:xxxxxxxxxx:cluster/blog-cluster".
You can verify all configured contexts by analysing ~/.kube/config file.
Troubleshooting errors
If your IAM user (configured in AWS CLI) is not authorized on the EKS cluster then you will see this error –
# kubectl get pods --all-namespaces
error: You must be logged in to the server (Unauthorized)
Make sure your IAM user is authorised in the EKS cluster. This can be done by adding user details under mapUsers field in the configmap named aws-auth residing in kube-system namespace. You will be able to fetch and edit it with the user who built the cluster in the first place. By default, AWS adds the IAM user as system:masters in config map who built the cluster. You have to configure the same IAM user with kubectl and edit this configmap for adding other IAM users to the cluster.
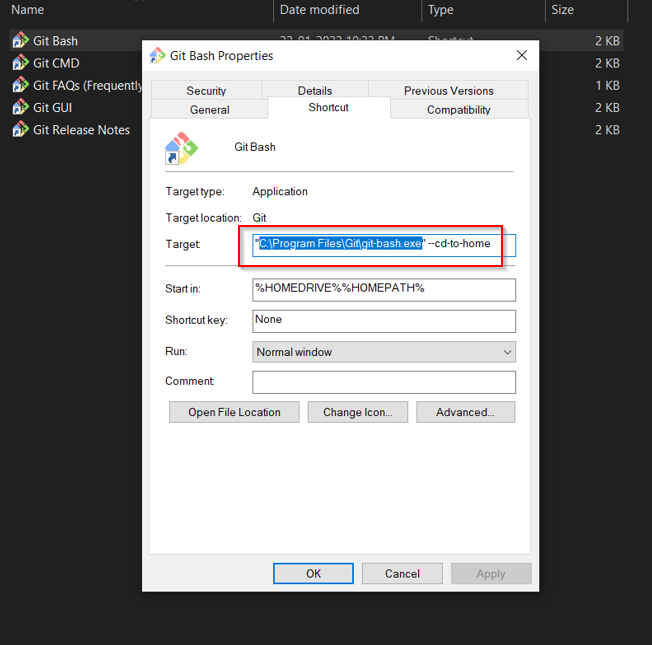
A quick post on how to resolve an issue with Gitbash that prevents MFA prompts while using AWS CLI.
MFA GitBsah issue.
Problem
GitBash under the hood uses winpty emulator for providing a bash experience on windows. Winpty does not work well with AWS CLI especially when dealing with MFA prompts. Hence you need to replace this with bash.exe and you should be good.
Procedure
Go to the Windows start menu and search for Git Bash. Click on Open file location.
Right click on the shortcut and select Properties
Under properties change the target from “C:\Program Files\Git\git-bash.exe” to “C:\Program Files\Git\bin\bash.exe“
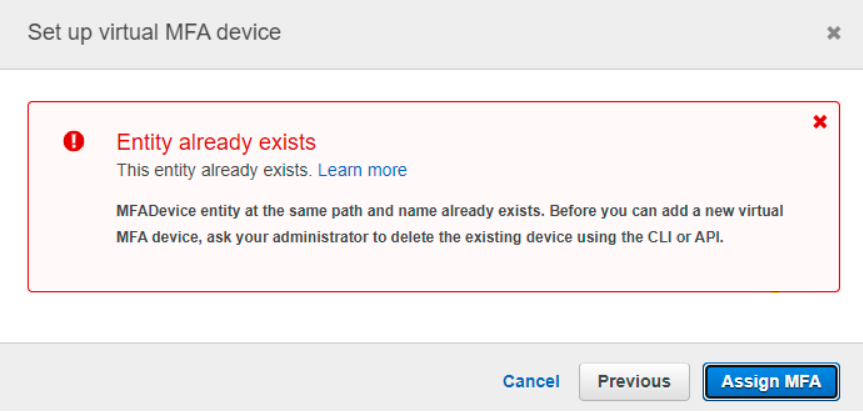
The user is not able to register an MFA device. When a user tries to assign a new MFA, IAM throws an error –
This entity already exists. MFADevice entity at the same path and name already exists. Before you can add a new virtual MFA device, ask your administrator to delete the existing device using the CLI or API.
MFA assignment error
Whereas if you as admin or even user check the AWS console it shows Assigned MFA device as Not assigned for that user.
Resolution
As an administrator, you need to delete the MFA device (yes even if says not assigned) using AWS CLI. The performer needs to have IAM permission iam:DeleteVirtualMFADevice on to the given resource to update the IAM user’s MFA.
Run below command from AWS CLI –
# aws iam delete-virtual-mfa-device --serial-number arn:aws:iam::<AWS account number>:mfa/<username>
where –
AWS account number is account number where user exists
username is IAM username of that user
This should clear out the error message and the user should be able to register a new MFA device.
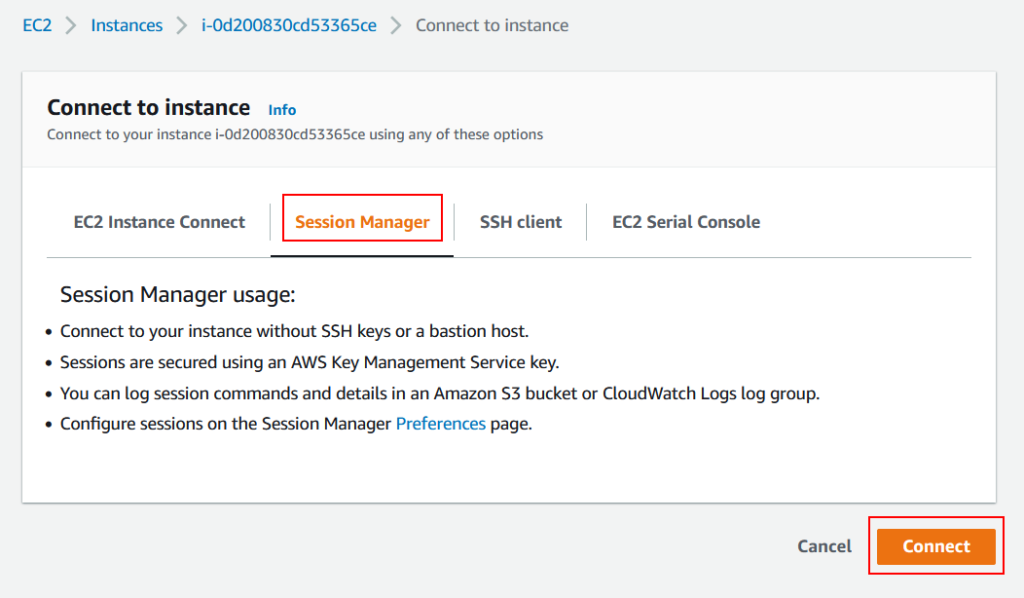
A quick reference to configure EC2 for Session Manager in AWS
EC2 session manager!
Ok this must be a very basic post for most of you and there is a readily available AWS doc for it, but I am just cutting it short to list down steps for achieving the objective quickly. You should go through the official AWS doc to understand all aspects of it but if you are on the clock then just follow along and get it set up in no time.
Checklist
Before you start, make sure you checked out these minimum configurations to get going.
Your EC2 is running supported Opertaing System. We are taking example of Linux here so all Linux versions that supports AWS Systems Manager supports session manager.
SSM agent 2.3+ installed on system. If not, we got it covered here.
Outbound 443 traffic should be allowed to below 3 endpoints. You must have this already covered since most of the setups has ALL traffic aalowed in outgoing security group rule. –
ec2messages.region.amazonaws.com
ssm.region.amazonaws.com
ssmmessages.region.amazonaws.com
In a nutshell, probably point 2 is the one you need to verify. If you are using AWS managed AMI then you got it covered for that too! But, if you are using custom-built, home-grown AMI then that might not be the case.
SSM agent installation
It’s a pretty basic RPM installation as you would do on any Linux platform. Download package relevant to your Linux version from here. Or global URLs for Linux agents –
If you do not have access to EC2 (Key lost or EC2 without keypair) then probably you need to re-launch the EC2. If your EC2 is part of an auto-scaling group (ASG) then it makes sense to add these commands in the user-data script for the launch template and launch a new EC2 from ASG.
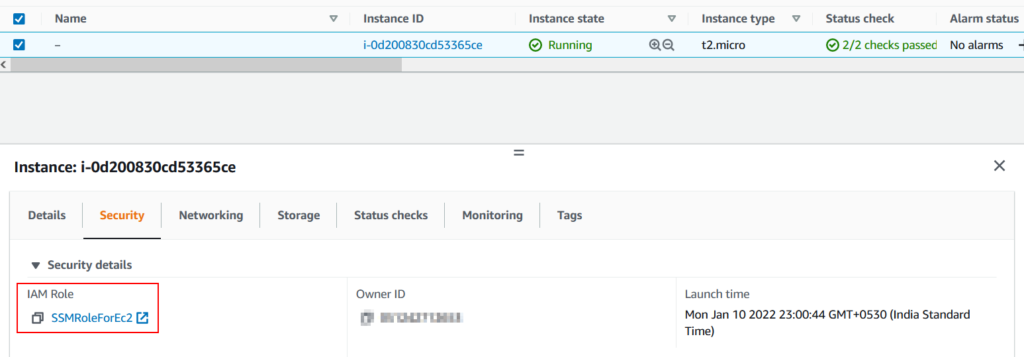
Instance role permissions
Now the agent is up and running. The next step is to authorize the AWS Systems Manager service to perform actions on EC2. This is done via Instance Role. Create the IAM instance role with below IAM policy:
You can scope it down to a particular resource if you want. You can even add KMS encryption-related permissions in it if you are planning to encrypt session data using KMS encryption. An example can be found here.
Once done attach the role to EC2. If EC2 is already having a role attached to it then add the above policy to the existing role and you should be good.
In this post, I will be sharing various resources to help you prepare for the CKA exam. In addition, feel free to add resources you know in the comments section, which may help fellow readers.
Exam details
Offered by: The Cloud Native Computing Foundation (CNCF)
Duration: 2 hours
Type: Complete tasks on Linux CLI (Practical)
Number of questions/tasks: 15-20 (I had 17)
Mode: Online proctored
Cost: $375 (that includes one free retake). Watch out over LinkedIn or internet for coupons. They got good deals on black friday as well.
Result: It will be available in 24 hours from the exam completion.
You are allowed to open one additional browser tab to access K8s docs, K8s Github or K8s blog. You should not be clicking/opening any links other than these domains that includes K8s forum as well.
Study journey
Having Linux and container background helps picking up Kubernetes world quickly. No prior cloud experience is required.
If you are not familier with containerization, its good to look into it before starting with Kubernetes. Docker containers are the best place to get started with.
Practise course labs heavily. You may go through course quickly to understand the Kubernetes world but you need to spend more time on practising Kubernetes on CLI.
Once you are good with the theory and understood all aspects of Kubernetes world, Labs are the only places where you should spend all of your study time.
Once you are through all the scenarios/tasks provided by online courses, you can think of your own custom scenarios and try implementing them.
Tips
Practise! Practise!! Practise!!! The more you are familiar with the CLI and commands, the more time you will save during the exam. In addition, it helps to build your muscle memory for command arguments and gain those extra seconds during the exam.
CKA requires you to complete the given tasks in the Linux terminal (Ubuntu) CLI on a shared Kubernetes cluster setup. So, having good Linux background is added plus! Moreover, it helps you in navigating through CLI, editing files and save a lot of time.
Make use of -h frequently! If you are not sure about the command arguments, use a -h flag that lists arguments along with example commands. You can directly copy those example commands and edit them accordingly before executing. A quick way to get the job done rather than navigating through kubectl commands on Kubernetes documentation
Try to complete tasks using imperative commands rather than building spec files.
Read the question carefully and completely before creating any objects. Keep an eye on the namespaces mentioned in the questions. Assume default namespace when no specific namespace is mentioned.
Verify created objects to make sure they carry properties asked in questions. For pods, make sure they reach running state before proceeding.
Setting alias in Linux shell is one of the famous tips you will come across over the internet. Use it according to your comfort. I did not use it.
Always make sure you run the given context commands at the start of each task. It makes sure you are on the right cluster to perform the task.
Always make sure to return to the main terminal if you are doing ssh to other nodes for performing the tasks.
For Tasks mentioning sudo -i for root privileges, it’s good practice to switch to root as soon as you log in to the respective node rather than finding out you are not run after running some commands and investing time there!
If you are not familiar with Linux editors like vi, edit your spec files in the exam provided notepad and then copy the final version of the config directly on the terminal within the file rather than running around in Linux editors and wasting time.
Get familiar with copy, paste operations in the terminal. There are different key combinations depending on the operating system. Refer exam handbook for the same. Then, practise using those key combinations.
Use kubernetes.io/docs heavily during practice. If you are stuck at something, always try to search and get information from Kubernetes official documentation. This will make you comfortable navigating through the documentation site and hence saves some time during the exam. In addition, you will know exact keywords to search and exact links to click on topics you had a hard time studying.
It’s the student’s responsibility not to click/open any other sites than the allowed three. Search in K8s documentation may yield results with links to the K8s forum. You should not be clicking them. Make a habit of checking links before opening to avoid issues during the exams.
Please note that the exam simulator you get along with your exam booking has more challenging questions than the actual exam. They mentioned it explicitly there. So if your morale goes down pretty quickly, then it’s best not to check those questions just before the exam :P. They aim more at getting an in-depth understanding of how things run under the hood.
A short howto on configuring AWS CLI to switch roles
AWS CLI Switch Roles configuration
Requirement:
You have one AWS account that needs to switch roles before executing things on AWS. It’s an easy method on AWS console, but how to switch roles in AWS CLI.
Solution:
Let’s consider the below setup-
AWS IAM account with programmatic access – user101
Same IAM account having sts:AsumeRole permissions.
AWS IAM role for above said IAM user to assume (same or cross-account)- role101
Start with configuring the AWS CLI in a standard way.
$ aws configure --profile user101
AWS Access Key ID [None]: AKIAQX3SNXZGUQFOSK4T
AWS Secret Access Key [None]: 33hjtNbOq9otA/OjBgnAcawHQjxTKtpY465NrDxR
Default region name [us-east-1]: us-east-1
Default output format [None]: json
In some cases, your AWS environment must have MFA restrictions in place where the user user101 must have MFA enabled to switch to the role role101. In such a scenario, your role profile in credentials files should include MFA device ARN as well like below –