Learn about the difference between /etc/passwd and /etc/shadow files in the Linux system. 9 points to understand the comparison of these two files.
/etc/passwd vs /etc/shadow
Its one of the Linux beginners interview question explain the difference between /etc/passwd and /etc/shadow files or compare passwd and shadow files in Linux. Basically both files serve different purposes on the system so it’s not completely logical to compare them but still if you want to we have this article for you explaining /etc/passwd vs /etc/shadow.
Before reading ahead, if you are not sure about these files read our articles explaining these files field by field.
File formats are the same i.e. fields separated by colons & new row for each user. But the number of fields is different. passwd file has 7 fields whereas the shadow file has 8 fields.
All fields are different except for the first one. It’s the same for both files and is the username.
/etc/passwd file aims at user account details while /etc/shadow aims at the user’s password details.
the passwd file is world-readable. shadow file can only be read by the root account.
The user’s encrypted password can only be stored in /etc/shadow file.
pwconv command is used to generate a shadow file from the passwd file if it doesn’t exist.
passwd file exists by default when the system is installed.
passwd file information is more of a static (home directory, shell, uid, gid which hardly changes)
shadow file information changes frequently since its related to password and user password changes frequently (if not, password policies are loosely defined!)
Listing new features in RHEL7. These 7 new features making RHEL7 stand out from its predecessor.
New features in RHEL7
Its been a while RHEL7 is launched and nicely accommodated in Linux world by now. What’s new in RHEL7? What is the difference between RHEL7 and its precedence versions? these kinds of questions are flowing through interviews these days. So thought of jotting them down. In this post I will quickly walk through some new key features launched in RHEL7 by Red Hat.
What’s new in RHEL7?
RHEL7 officially released in June 2014 with codename Maipo. It took time for the market to absorb this new release since there are many new features launched in this release. Red Hat launched many new ways, commands to do traditional stuff. We are going to see them now –
The default file system is XFS. RHEL6 was launched with EXT4 as the default file system. XFS is a highly scalable, high-performance file system. XFS supports metadata journaling, which helps in quicker crash recovery. This means file system checks will take very little time. The XFS file system can be defragmented and extended while mounted. This makes it more admin friendly in a production environment since it avoids downtime of file systems for activities. Supports only 64 bit systems.
Introduction of systemctl. A new way to manage services on RHEL7 is systemctl. Older service and chkconfigcommand is being replaced with systemctl.
Run levels being called as targets. In RHEL7 run levels are called targets. Default target (run-level) is defined in /etc/systemd/system/default.target.
Fast boot. RHEL7 boots faster than its predecessors. This is achieved by simultaneously starting services that are not dependent on each other. In older versions, services used to start one after another. So if one service stuck or delays to start it subsequently delays the following process and boot time. This hurdle is removed in RHEL7 allowing it to boot much faster.
New system service manager: systemd. The former init process is no more PID 1 or first process. Systemd is introduced which controls standard base init scripts.
Bigger filesystem limits. RHEL7 now supports filesystem size up to 500TB. This limit is also the same for an individual file. This is due to the XFS file system on a 64-bit machine. RHEL6 supports the 16TB filesystem.
New firewall identity. Former firewall iptables now replaces by firewalld (Firewall Dynamic). iptables still exist in the system and you can disable firewalld and use iptables.
These are key differences in the new RHEL7 release. apart from this there are many new things added in RHEL7. The whole list is compiled by Red Hat here.
Let us know your suggestions/feedback in comments section below!
The story behind popular Linux mascot penguin named TUX! Read who, when, and how it was discussed, designed, and released.
Linux mascot penguin : TUX
One of my blog readers sent me a Penguin picture (of TUX) on messenger and asked how it is related to Linux. So I decided to write this short post about Linux mascot.
Linux mascot penguin : TUX
This post describes who is a tux, How it was designed, and when it was released as Linux mascot.
Linux official mascot is Penguin named TUX! TUX is an abbreviation for Torvalds’s Unix or Tuxedo (Black dinner suit which you can think of whenever you see penguin). The concept came from obviously none other than Linux’s creator Linux Torvalds.
The mascot was first designed by Larry Ewing in 1996 along with Alan Cox. Further it was finalized by Linux Torvalds. The mascot was discussed and refined on the Linux kernel mailing list. The mascot was first publicly released on GIMP by Larry. It’s said that, it was inspired by one of the penguin images by Nick Park on the FTP site.
Another inspiration said to be disease Penguinitis which Torvalds claims in Linux kernel discussion groups after penguin nibbled his finger in one close encounter. Penguins make you stay awake later in the night thinking about penguins. Some people in the Linux community believe it’s just a story but hey it’s good to have it behind mascot!
There were few Linux logo competitions held too which had a good response. Few logos from these competitions can be viewed here.
There are emails exchanged for this mascot available online. One of Linus Torvalds reply has his idea about mascot penguin. In his own words :
So when you think “penguin”, you should be imagining a slightly overweight penguin (*), sitting down after having gorged itself, and having just burped. It’s sitting there with a beatific smile – the world is a good place to be when you have just eaten a few gallons of raw fish and you can feel another “burp” coming.
(*) Not FAT, but you should be able to see that it’s sitting down because it’s really too stuffed to stand up. Think “bean bag” here.
You can view this email here on the Linux Kernel Mailing List thread. Interesting? You can surf May 1996 and after archives to read interesting conversations emails about Linux mascot. LKML is still an active list and you can see recent mails about Linux kernel development on their website.
So now you know the story behind TUX (Linux logo/mascot)! Now on, you will never see this penguin the way you used to since you know it does have a story, discussions behind its existence!
Learn different process states in Linux. Guide explaining what are they, how to identify them, and what do they do.
Different process states
In this article we will walk you through different process states in Linux. This will be helpful in analyzing processes during troubleshooting. Process states define what process is doing and what it is expected to do in the near time. The performance of the system depends on a major number of process states.
From birth (spawn) till death (kill/terminate or exit), the process has a life cycle going through several states. Some processes exist in process table even after they are killed/died, those processes are called zombie processes. We have seen much about the zombie process in this article. Let’s check different process states now. Broadly process states are :
Running or Runnable
Sleeping or waiting
Stopped
Zombie
How to check process state
top command lists total count of all these states in its output header.
See highlighted row named Tasks above. It shows the total number of processes and their state-wise split up.
Later in above top output observe column with heading S. This column shows process states. In the output we can see 2 processes in the sleeping state.
You can even use ps command to check process state. Use below syntax :
# ps -o pid,state,command
PID S COMMAND
1661 S sudo su -
1662 S su -
1663 S -bash
1713 R ps -o pid,state,command
In the above output you can see column titled S shows state of the process. We have here 3 sleeping and one running process. Let’s dive into each state.
Process state: Running
The most healthy state of all. It indicates the process is active and serving its requests. The process is properly getting system resources (especially CPU) to perform its operations. Running process is a process which is being served by CPU currently. It can be identified by state flag R in ps or top output.
The runnable state is when the process has got all the system resources to perform its operation except CPU. This means the process is ready to go once the CPU is free. Runnable processes are also flagged with state flag R
Process state: Sleeping
The sleeping process is the one who waits for resources to run. Since its on the waiting stand, it gives up CPU and goes to sleep mode. Once its required resource is free, it gets placed in the scheduler queue for CPU to execute. There are two types of sleep modes: Interruptible and Uninterruptible
Interruptible sleep mode
This mode process waits for a particular time slot or a specific event to occur. If those conditions occur, the process will come out of sleep mode. These processes are shown with state S in ps or top output.
Uninterruptible sleep mode
The process in this sleep mode gets its timeout value before going to sleep. Once the timeout sets off, it awakes. Or it awakes when waited-upon resources become available for it. It can be identified by the state D in outputs.
Process state : Stopped
The process ends or terminates when they receive the kill signal or they enter exit status. At this moment, the process gives up all the occupied resources but does not release entry in the process table. Instead it sends signals about termination to its parent process. This helps the parent process to decide if a child is exited successfully or not. Once SIGCHLD received by the parent process, it takes action and releases child process entry in the process table.
Process state: Zombie
As explained above, while the exiting process sends SIGCHLD to parents. During the time between sending a signal to parent and then parent clearing out process slot in the process table, the process enters zombie mode. The process can stay in zombie mode if its parent died before it releases the child process’s slot in the process table. It can be identified with Z in outputs.
So complete life cycle of process can be circle as –
Learn what is tmpfs, what is the use of tmpfs, what is swap, what is the use of swap and differences between tmpfs, and swap.
tmpfs and swap
On the social share of our last post about RAM disk in Linux we got a comment “what is the difference between RAM disk and SWAP?” So I decided to explain it a bit in an article on our blog. In this post I will try to explain how swap and RAM disk i.e. tmpfs/ramfs is different and how they work.
What is tmpfs?
Tmpfs also mounted as shared memory /dev/shm. tmpfs is a portion of a virtual memory mounted as a file system that helps to speed up applications. It normally is used to transfer data between programs. It appears as a file system but it does not use persistent devices such as a hard disk. Instead it uses virtual memory (a portion of a RAM).
That’s why if you create any file in tmpfs it’s not created on your system disks but in your memory. Whenever you un-mount tmpfs, everything within is lost. Its volatile storage. Even if you add an entry of tmpfs to re-mount at boot, it will be mounted blank. Data does not persist over reboots or shutdowns in tmpfs.
What is SWAP?
swap is a portion of your hard disks used to extend RAM. Its roughly extended RAM by use of persistent storage device. swap only comes in action once your RAM (physical memory) is full. The normal thumb rule is the size of the swap should be double of your physical ram size. But these changes depend on the conditions and system you have. Read how to create extra swap here & check swap on the server.
Even if it uses persistent devices, it still is a volatile memory. It does not hold data over reboot or shutdowns. Since it plays the role of RAM, its characteristics are still of ram even if it uses hard disks.
Difference between tmpfs and swap
tmpfs uses memory while as swap uses persistent storage devices.
tmpfs can be viewed as a file system in df output whereas swap doesn’t
swap has general size recommendations, tmpsfs not. tmpfs size varies on system purpose.
tmpfs makes applications fasters on loaded systems. swap helps the system breathe in-memory full situations.
swap full indicates system heavily loaded, degraded performance, and may crash. tmpfs being full not necessarily means heavy load or prone to crash.
tmpfs is enhancement whereas swap is a must-have feature!
Short tutorial explaining what is RAM disk and how to create a RAM disk in Linux. It also includes differences between ramfs and tmpfs.
RAM disk in Linux
Recently one of our readers asked “how to create a RAM disk in Linux?”. So I thought of writing this small tutorial which will help you to understand what is a RAM disk, what is the use of it and how to create a RAM disk in Linux.
What is RAM disk?
Roughly RAM disk can be termed as a portion of your RAM mounted as a directory. It uses tmpfs or ramfs. Refer below table for the difference between ramfs and tmpfs.
ramfs
tmpfs
Old type
New type and replacing ramfs now
Can not be limited in size
Size limit can be defined
Since can not be limited may lead to system crash
Once limit reached, disk full error written. No system crash issue.
Entry is not visible in ‘df’ output. Need to calculate by using ‘Cached’ number in ‘free’ output.
Can be seen in ‘df’ command output
Work mechanism as file system cache
Work mechanism is as partition of physical disk
RAM disk is a very high speed, high performance and almost zero latency area to store application files. Due to its performance-oriented nature, its mostly used for temporary data like caching application files.
How to create RAM disk?
RAM disk can be created in simple two steps. One is to create a directory on which it should be mounted and the second step is to mount it on that directory using specific FS type. Make sure you have enough free RAM on the system so that portion of it can be used in RAM disk. You can check it using free command.
Lets create directory /mnt/ram_disk and mount RAM disk on it.
In above mount command, -t should be followed by tmpfs or ramfs type. For ramfs, size is the starting size of RAM disk since ramfs have limitless size. Size followed by the name of the disk (of your choice ex. new_ram_disk). You can verify if it mounted properly using df command.
You can see newly created tmpfs of 1GB size is mounted on /mnt/ram_disk (highlighted above).
You can add below entry in /etc/fstab as well to persist it over reboots as well. But keep in mind that data within RAM disk flushes for each reboot since its backed memory is volatile.
Learn what is hostname, how to set hostname and how to change hostname in Debian and RedHat based Linux systems.
Learn about hostname in Linux
The hostname is a prime identity of Linux servers in the human world! Obviously, the IP address is the main component to identify the system in the environment. In this article, we are going to see anything and everything about the hostname. We will walk through what is the hostname, how to set hostname, how to change hostname etc. Let’s start with the basics of the hostname.
What is hostname
The hostname is the humanly readable identity of the server. Any server is identified by IP address in the network but to identify easily hostname is also given. Normally FQDN (Fully Qualified Domain Name) is expected for the system but even Domain name (the name before the dot) is also fine for systems under private networks. The hostname can be alpha-numeric
Generally hostname standards to the maximum of 255 bytes long. But normally people prefer to keep it 10-12 characters long so that it’s easy to remember. Kernel variables _POSIX_HOST_NAME_MAX or HOST_NAME_MAX defines your current max limit of hostname. You can get their values using getconf a command like below :
# getconf HOST_NAME_MAX
64
How to set hostname in Linux
A quick command in all-new Linux distros is hostnamectl. Use set-hostname switch and your new hostname as an argument.
In above files, you can only view current hostname (being used by the live kernel) under proc file only. Rest all files are used to lookup or set hostname at boot time. So if you change hostname using hostname command then it won’t reflect in rest files. It will only reflect in the proc file.
You can set the hostname of your choice in /etc/hostname or /etc/sysconfig/network and restart network service to notify kernel about it.
How to change hostname in Linux
The current hostname can be checked by typing hostname command without any argument. The hostname can be changed by simply using hostname command followed by the name of your choice.
Cautions : Do not change hostname on live production systems!
On Suse systems: Edit file /etc/HOSTNAME and add hostname in it. There will be no parameter and value format. Only you have to enter hostname like below :
# cat /etc/HOSTNAME
kerneltalks.com
Change hostname permanently in clone, template VM & cloud clones
If you have a system which is prepared using clone, template from VMware or cloud clone deploy then you should do the following :
Edit file /etc/cloud/cloud.cfg and change parameter 'preserve_hostname' to true. You can do it using one-line sed script as below :
root@kerneltalks # sed --in-place 's/preserve_hostname: false/preserve_hostname: true/' /etc/cloud/cloud.cfg
Also, change DHCP related parameter DHCLIENT_SET_HOSTNAME in file /etc/sysconfig/network/dhcp to no. So that hostname wont be changed by DHCP in the next reboot. Again, you can use one line sed to do that as below :
root@kerneltalks # sed --in-place 's/DHCLIENT_SET_HOSTNAME="yes"/DHCLIENT_SET_HOSTNAME="no"/' /etc/sysconfig/network/dhcp
That’s it. These are two extra steps you need to take on cloud or VM servers.
How to configure FQDN in Linux
Another thing around the hostname is to set FQDN for Linux server i.e. Fully Qualified Domain Name. Generally you should be doing in via DNS in your environment but /etc/hosts always get checked first. So its good practise to define FQDN at /etc/hosts file
Use <IP> <FQDN> <Hostname> format to add/edit entry in /etc/hosts and you are good to go. Sample entry below –
An article explaining how to tune kernel parameters in the Linux system using command or using a configuration file.
Tune kernel parameters in Linux
In this article we will be discussing how to set or tune the kernel parameter in any Linux system. There are many ways you can do it like setting them in their configuration files or using a system control command sysctl.
sysctl command is used to configure kernel parameters at runtime. Your current kernel parameters values can be viewed with -a switch.
In the above output you can see parameters on left and their current value on the right. Parameters are sorted with alphabetical order and both columns in output are delimited with = sign so that you can sort this output easily using this delimiter.
There are a few parameters you can even view using the proc file system. You can cat their respective files and view values.
# cat /proc/sys/kernel/shmmni
2048
In above example we can see shmmni value is set to 2048.
How to tune kernel parameter
To change the kernel parameter you can define it under configuration file /etc/sysctl.conf and it will be applied at the next reboot. You need to define parameter=value format in this file (ex. kernel.shmmni=4096).
Each new line represents a new parameter and value pair. Values in this file will be loaded at the next reboot. If you want to load this file immediately then you can can do it by using sysctl -p command. It will load /etc/sysctl.conf file in kernel. You can even define values with -w switch explained below.
To change the kernel parameter using sysctl, you should use a write switch -w along with parameter and value. In the below example we are changing kernel.shmmni value to 2048.
You can observe previously kernel.shmmni value was 4096, using -w we changed it to 2048. This change is immediate and does not need a reboot to comes in effect.
# cd lolcat-master/bin
# gem install lolcat
Successfully installed lolcat-42.24.0
Parsing documentation for lolcat-42.24.0
1 gem installed
This confirms your successful installation of lolcat!
lolcat command to rainbow color output!
Its time to see lolcat in action. You can pipe it with any output of your choice and it will color your command output in rainbow color (a few examples below)!
# ps -ef |lolcat
# date | lolcat
Want some more fun?
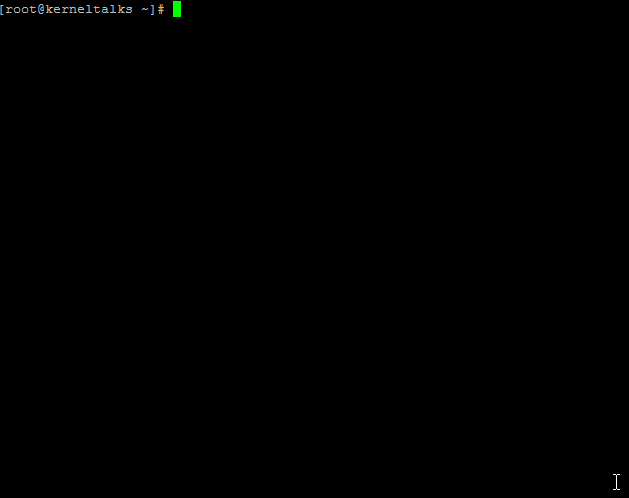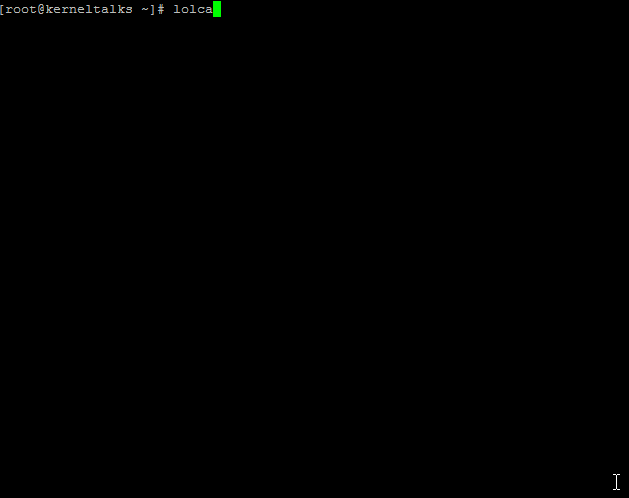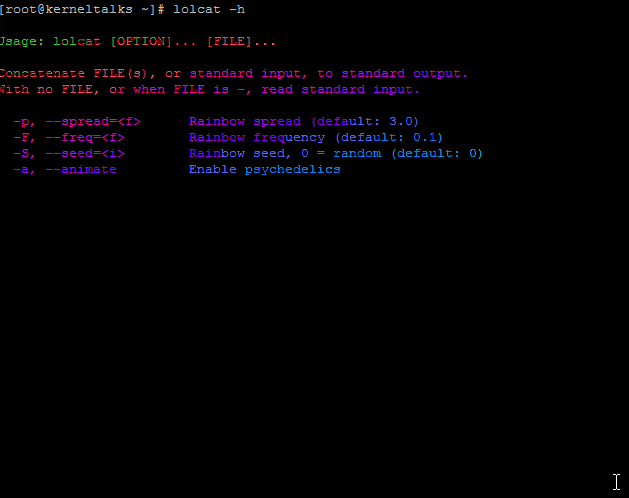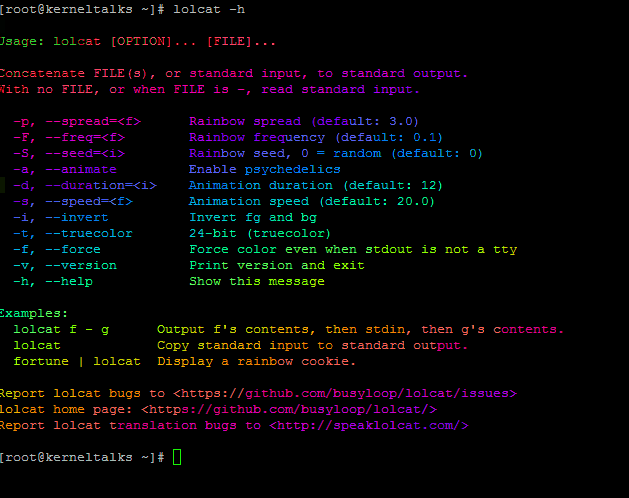
lolcat comes with few options which will make it more fun on the terminal. Run command with -d and duration and it will color your output in running mode.
Understand step by step how RHEL6 system boots. Walkthrough of RHEL6 boot process which lists all the tasks, activities happen during boot.
Anyone starting to learn Linux must know the boot process of Linux. Here is this post I will be explaining the boot process of Red Hat Enterprise Linux 6 i.e. RHEL6. In brief RHEL6 boot process can be summarized as below :
Powered on system loads boot loader once it completes POST. The boot loader in turn loads GRUB.
GRUB loads kernel into memory which further loads necessary modules and mount root partition as read-only.
Kernel invokes /sbin/init program and hands it over the boot process.
Init program loads all services as per run level and mounts mount points
The user is presented with a login screen.
Lets see each point in detail to understand RHEL6 boot process properly.
1. Power on and boot loaders:
Whenever the system turned on, it runs POST (Power on self-test) to check all hardware and its operating state. Once POST is cleared, the system runs BIOS. BIOS is a basic input-output system which is the lowest level interface for hardware. BIOS gets loaded in memory and checks system, connected peripherals, boot device path. Lastly, BIOS will load the first sector of the bootable disk in memory which is the MBR master boot record. Once MBR loaded, BIOS hand over boot control to it.
MBR is a small machine code that has a first stage boot loader. The first stage or stage-1 boot loader exists to locate the second stage boot loader and load it in memory only. The second stage or stage-2 boot loader is GRUB. Now boot control is with GRUB.
In UEFI based systems, BIOS is replaced by UEFI. It’s much powerful than BIOS. It has its own architecture, CPU, device drivers. It can mount and read file systems. Such systems have EFI partitions that have EFI’s own boot loaders which can load operating systems or stage-2 boot loaders.
2. GRUB:
GRUB displays a list of available kernels to the user in the graphical interface (like below). Its configuration file is /boot/grub/grub.conf (for BIOS) or /boot/efi/EFI/redhat/grub.conf (for UEFI). Here user can select its kernel to boot using arrow keys and press enter. If not then it will boot default selected kernel when selection time passes out. We can even reset the forgotten root password on this screen.
Once GRUB destined to load the kernel, it searches the kernel binary of it under /boot partition. The boot loader then places one or more appropriate initramfs (Initial RAM file system) images into memory (as seen in the above screenshot). The initramfs is used by the kernel to load drivers and modules necessary to boot the system. Once kernel and initramfs are loaded into memory, boot control is taken by the kernel.
3. Kernel:
Once kernel gets boot control, it quickly run though below tasks:
Initialize and configure memory, hardware, and attached peripherals.
Decompress initramfs into /sysroot and loads necessary drivers from it
Loads virtual devices related to file systems like LVM etc.
Free up memory by removing initramfs image
Create a root device, mount root partition (read-only)
Now, the kernel is fully loaded and operational. But no services loaded in the system yet so the system is not usable for humans. To load rest of the services kernel calls /sbin/init program and hand it over boot process to him.
4. Init program :
/sbin/init i.e. init process spawns very first in a system with PID 1 and it will be parent process for many system processes or zombie/defunct processes all the time. Init executes and calls various scripts as below :
Runs /etc/rc.d/rc.sysinit to start swap, set environment, FS checks, and some system initialization steps.
Process jobs in /etc/event.d directory which has run level specific settings
Set function library /etc/rc.d/init.d/functions
Runs background processes from their respective rc directories. Default specified in /etc/inittab. e.g. for run level 3, it will execute /etc/rc.d/rc3.d/ . Mostly rc directories are having symbolic links of start/stop services.
Once all processes started in the specified run level, init finishes, and spawns login screen.
5. Login screen:
Once init completes loading RC directories, it forks Upstart which in turns call /sbin/mingetty. mingetty will be forked for each virtual console. Run level 1 i.e. single user mode has 1 while run level 2 to 5 has 6 virtual consoles. /sbin/mingettystarts communication with tty devices, sets terminal modes, prints login screen (with messages if any), and prompt username to the user!
This completes RHEL6 boot process from power up to login prompt!