A quick article explaining all available options for creating a new AWS Lambda function and how to run it.


AWS Lambda is a compute service offered by AWS. It is treated as a serverless compute since the end-user did not have to worry about providing and maintaining the back-end infrastructure. Without further delay, let’s move ahead with creating the first AWS Lambda function.
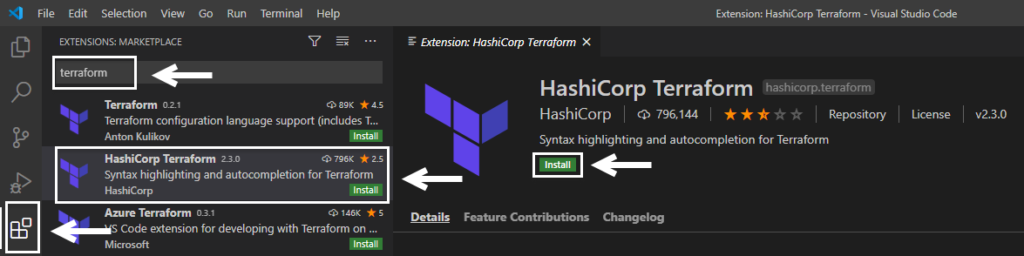
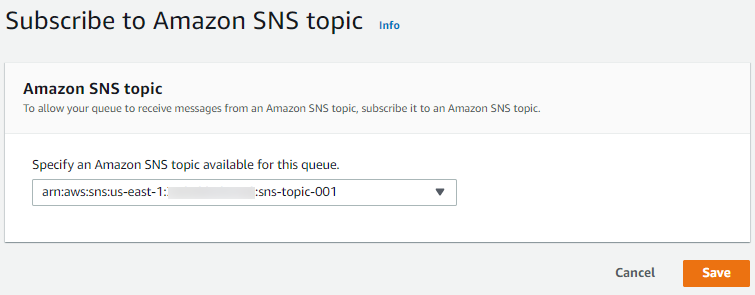
- Login to AWS Lambda console.
- Click on the Create function button.
- You should see wizard as below –

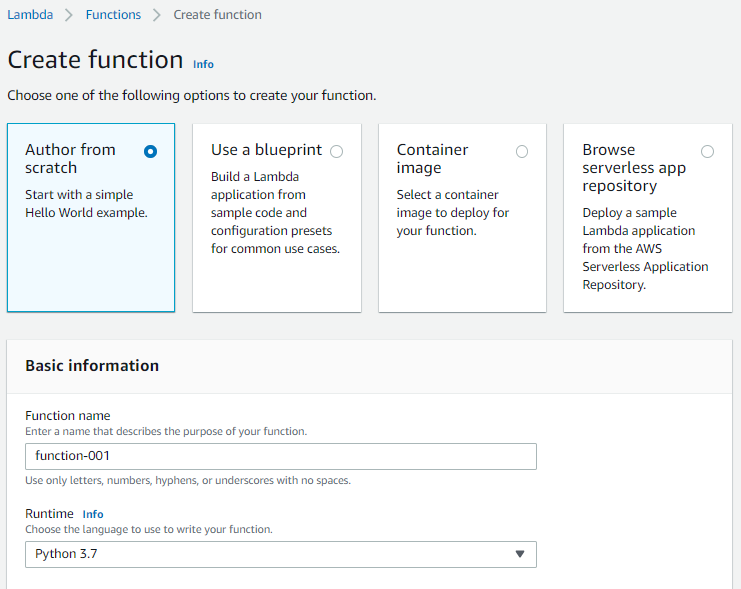
There are 4 ways you can choose to create AWS Lambda function –
- Author from scratch: Select the programming language of your choice and start writing the function code
- Use a blueprint: Use readymade function pre-written for you by AWS.
- Container image: Use a docker container image to deploy function
- Browse serverless app repository: Use complete application pre-written in Lambda.
- Basic information
- Function name: For identification purpose
- Runtime: Function’s coding lanuage. Select a supported language from the dropdown.
- Permissions: Arrange the Lambda function IAM role to access AWS resources on your behalf.

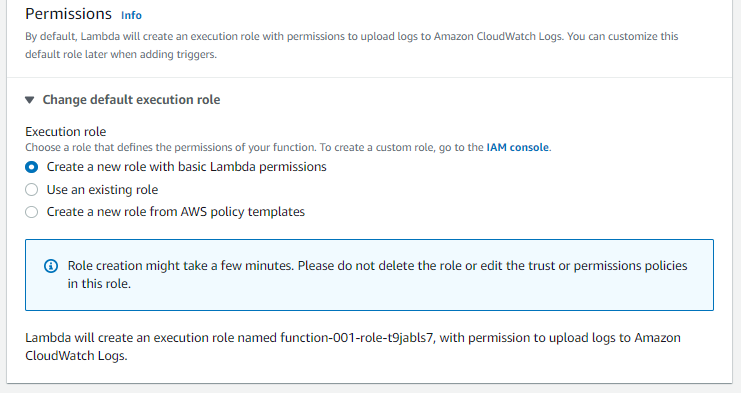
You can either use an existing role or let the wizard create a default permission role. If your code requires special permissions, it’s recommended to create a new role using policy templates to ensure that function has sufficient privileges to access AWS resources.

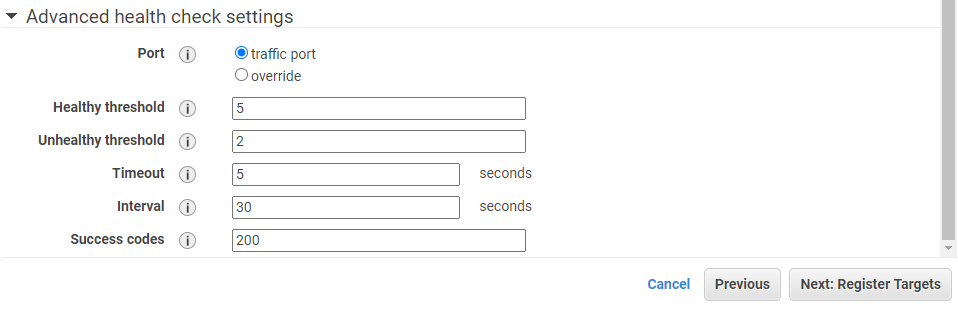
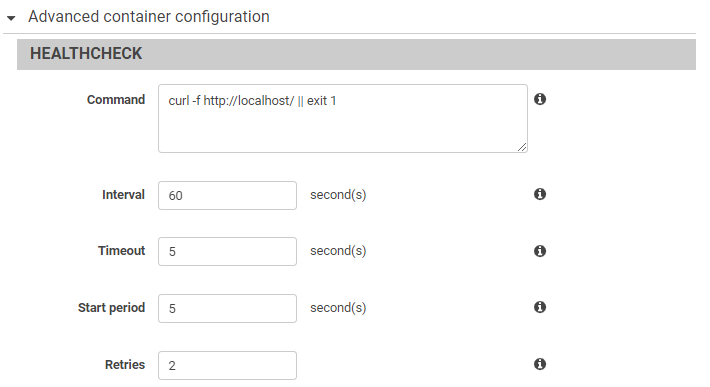
- Advanced settings
- Code signing: To ensure the integrity of the code and its source.
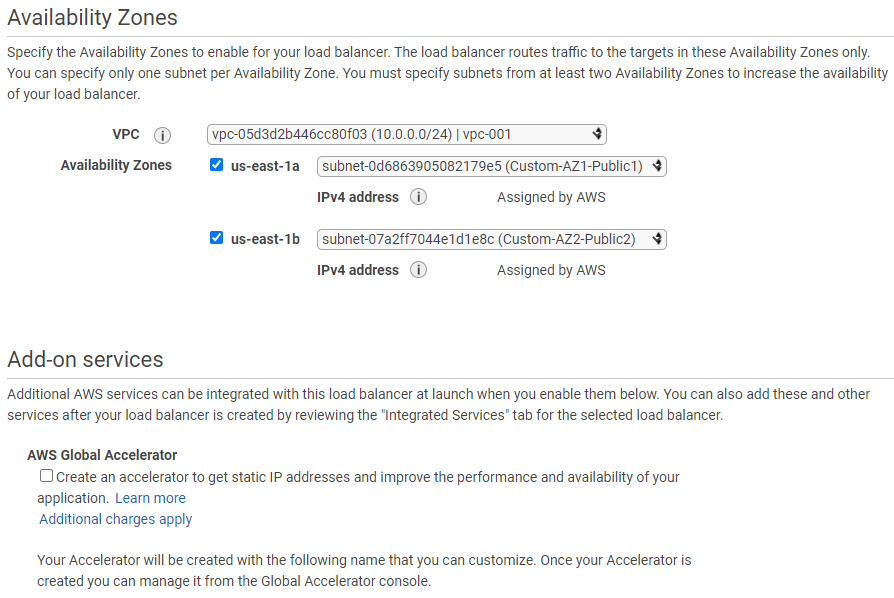
- Network: If function expected to have network access, then select VPC here and hence in turns select subnet, security group which will be applicable to function when it runs.
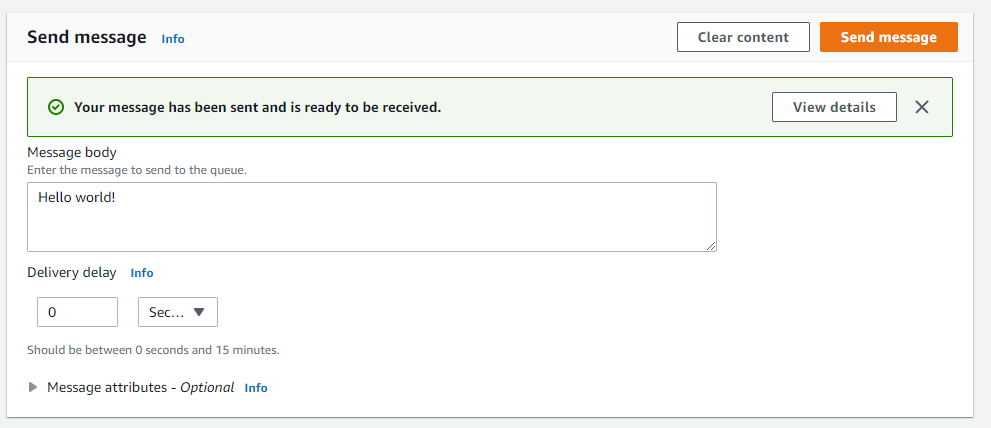
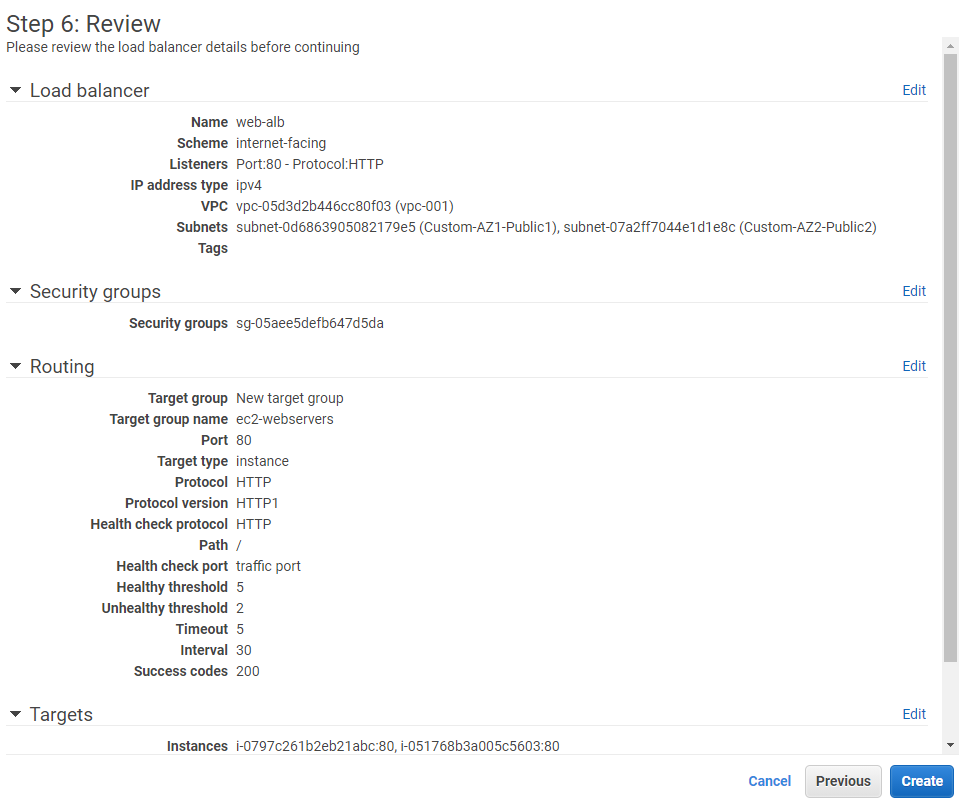
Click the Create function button.

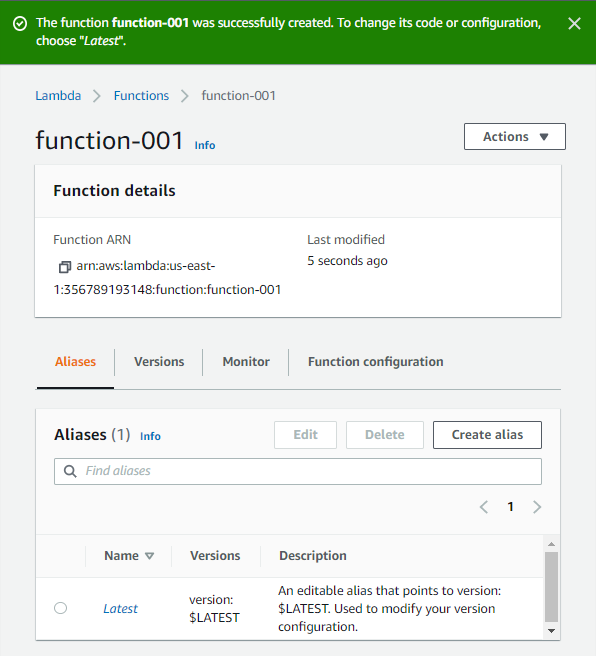
AWS Lambda function should be created. Click on the Latest alias to edit your code and test it.

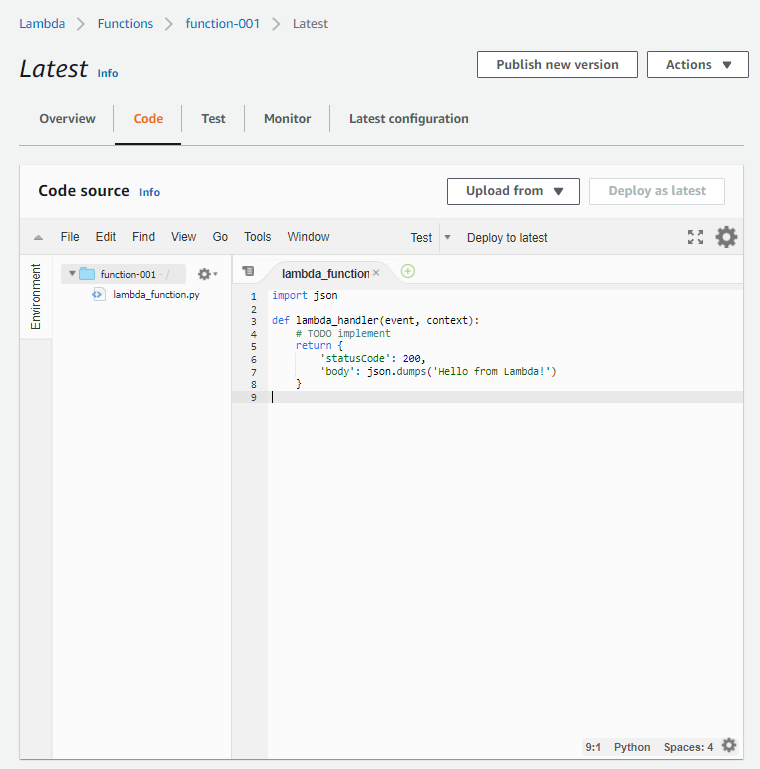
In latest alias, there are 5 tabs you can navigate.
- Overview: Overall details.
- Code: Edit code and code-related configurations.
- Test: Invoke test event for the Lambda function
- Monitor: Monitoring aspects in context to Cloudwatch
- Latest configuration: Various Lambda function related configurations.
Lets have a look at all these tabs one by one.
- Overview
- General configuration: Shows description, last modified, and Function ARN.
- Function visualization: Visual representation of a function.
- Code
- Code Source: In browser code editor. You can upload the code in a zip file or reference it from the S3 location.
- Runtime settings: Edit the code language.
- Code signing details: Edit code signing for code integrity.
- Layers: Edit or add layers to function.
- Test
- Test event: Create, format, or invoke test event.
- Monitor
- View CloudWatch metrics or CloudWatch logs insights.
- Latest configuration
- This is the biggest section of all. It has 5 subsections
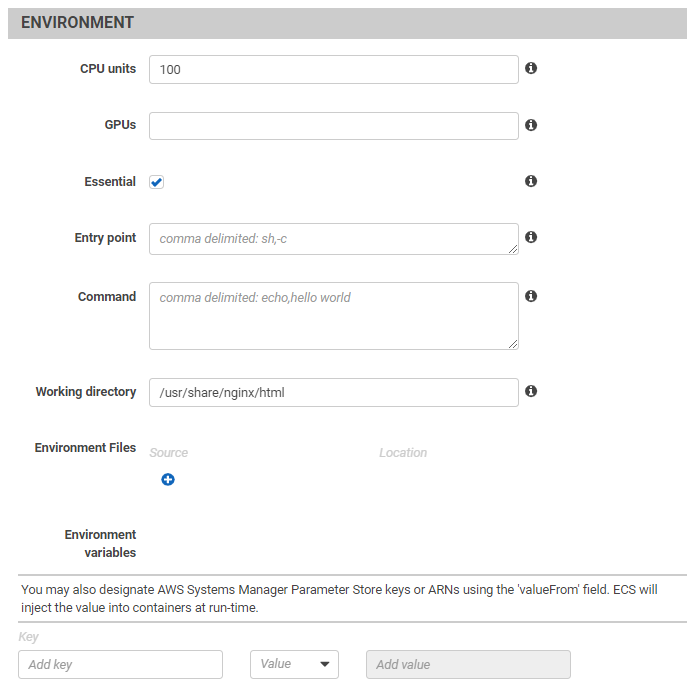
- General
- Environment
- Triggers
- Permissions
- Destinations
- This is the biggest section of all. It has 5 subsections
Lets go through each section one by one:
- General
- Basic settings: Edit below configurations
- Description
- Memory (MB): Memory allocated to function. CPU will be allocated in proportion to memory.
- Timeout: Max execution time. Limit: 15 mins.
- Execution role: IAM role being used by the function.
- Asynchronous invocations:
- Maximum age of event: To keep the unprocessed event in the queue.
- Retry attempt: Maximum number of retries after the function returns an error.
- Dead letter queue: SQS queue for sending unprocessed events for asynchronous invocations.
- Monitoring tools
- Amazon CloudWatch: By default enabled for AWS Lambda
- AWS X-ray: For analysis and debug purposes.
- CloudWatch Lambda insights: Enhanced monitoring.
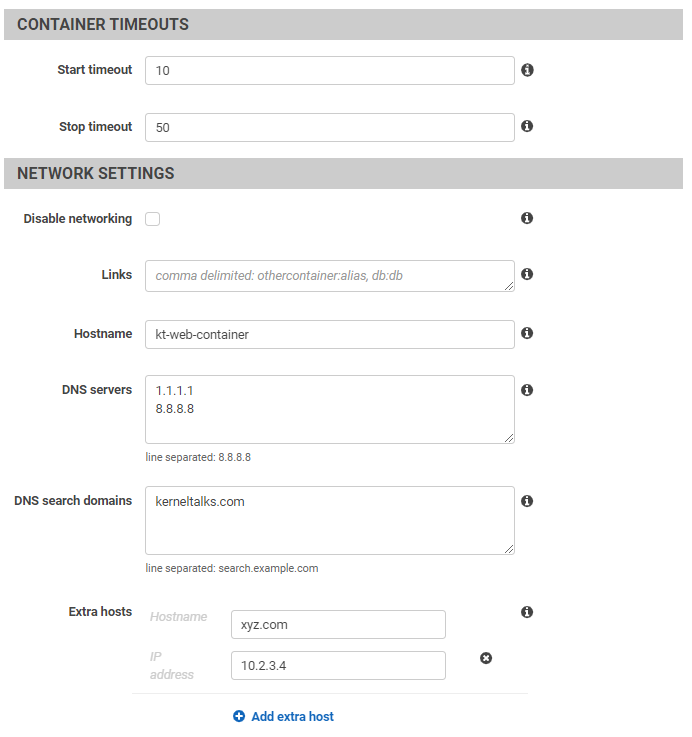
- VPC
- Edit VPC, subnet, security group for Lambda function if function required networking.
- State machines
- Step functions to orchestrate Lambda function.
- Database proxy
- Manage database connections if the function requires DB connectivity.
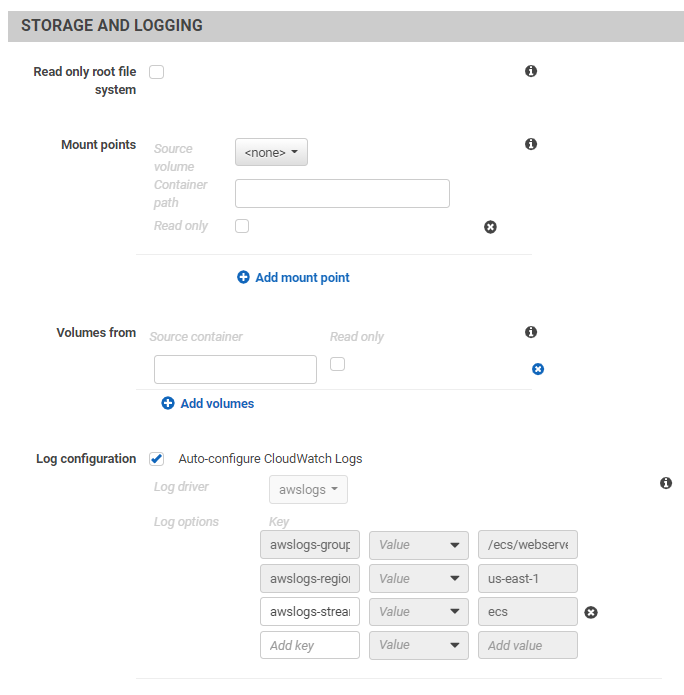
- Filesystem
- Make EFS available to Function.
- Basic settings: Edit below configurations
- Environment
- Environment variables: Set of key-value pairs to use as environment variables in function during execution.
- Triggers
- Add triggers to invoke the lambda function.
- Permissions
- IAM permissions via role or resource-based policies
- Destinations
- Configure destination for invocation records once function executes.
Since its a test function, I move ahead with all the defaults. Once everything is configured you are ready to test the fuction.
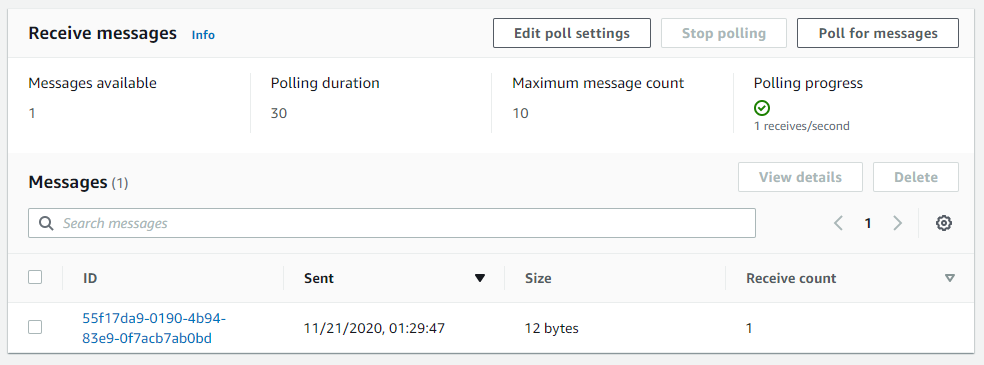
Click on the Test tab and then click the Invoke button to invoke the Lambda function test event.

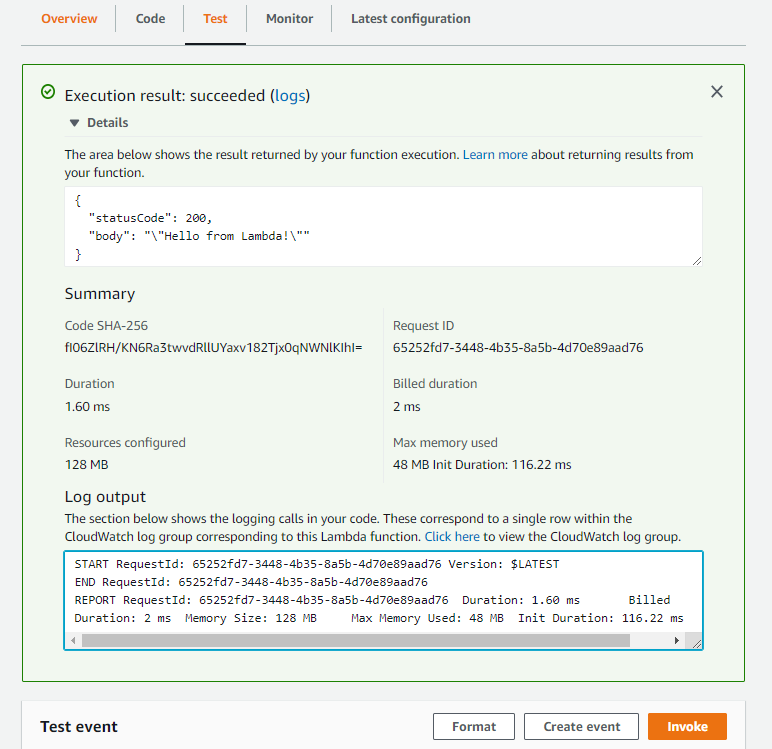
Test invokation results presented on same screen. The important details to look for are –
- Returned results by function
- Duration: Actual execution time
- Billed Duration: Billed execution time. Rounded to nearest 1ms.
- Max memory used
The log output at the end can also be viewed in CloudWatch log group.

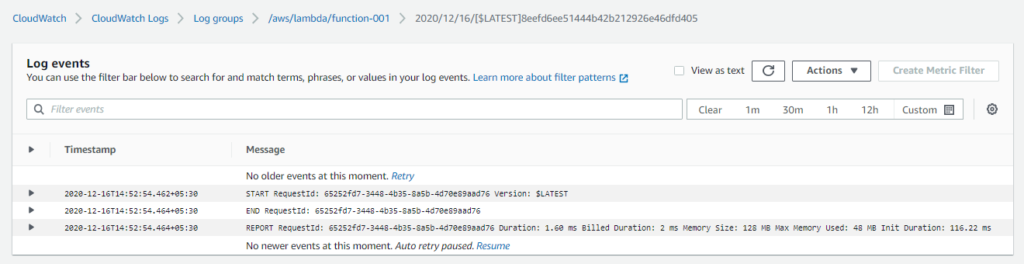
The bill amount is calculated using the amount of memory allocated and billed duration.
So that’s how you configure and execute simple basic Lambda functions for understanding the foundation of AWS Lambda!