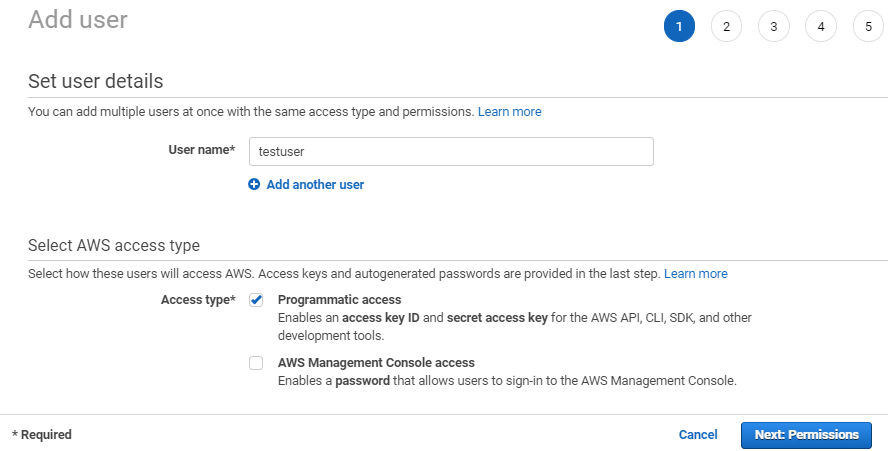
A quick post on how to add Capacity Providers in ECS clusters.


In our last article, we walked you through the basics of Capacity Providers. In this article, let’s create them to test their functionalities. You can create Capacity Providers and add them to the running ECS cluster without touching anything in the cluster.
Creating EC2 type Capacity Providers
Steps:
- Make sure you are running EC2 backed ECS Cluster.
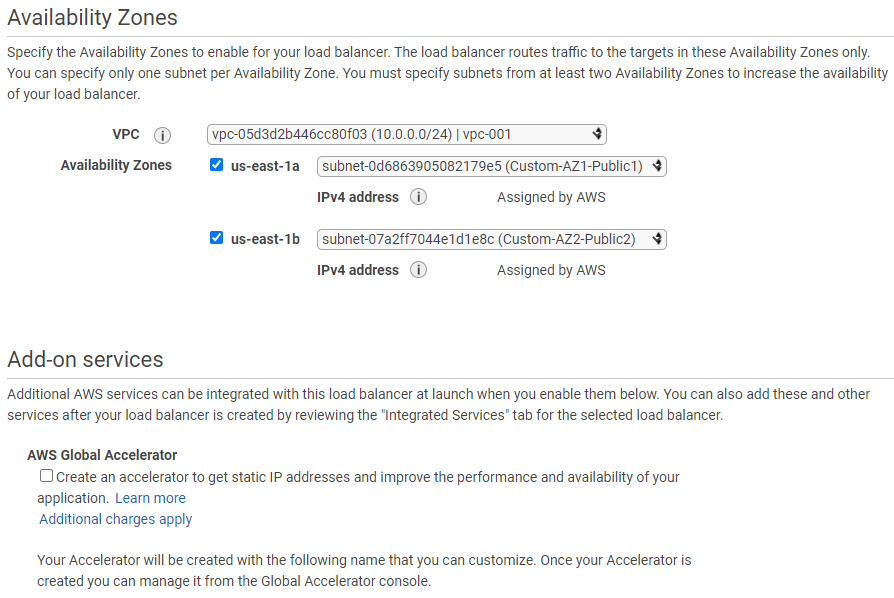
- Create new ASG using same launch template/configuration as existing ASG
- Create Capacity Provider
- Update cluster with newly created Capacity Provider.
For creating EC2 type Capacity Providers, you should use the new ASG. AWS does not recommend re-using the same ASG which is configured in ECS Cluster. You can use the same Launch template or Launch configuration and create a new ASG to be used by Capacity Providers. It makes it easy for Capacity Providers to keep track of EC2 instances instantiated by them.
While creating new ASG make sure –
- Desired and minimum capacity is set to zero.
- Maximum capacity is set to a non-zero number.
- Enable instance scale-in protection. So that scale in action does not terminate EC2s running tasks.
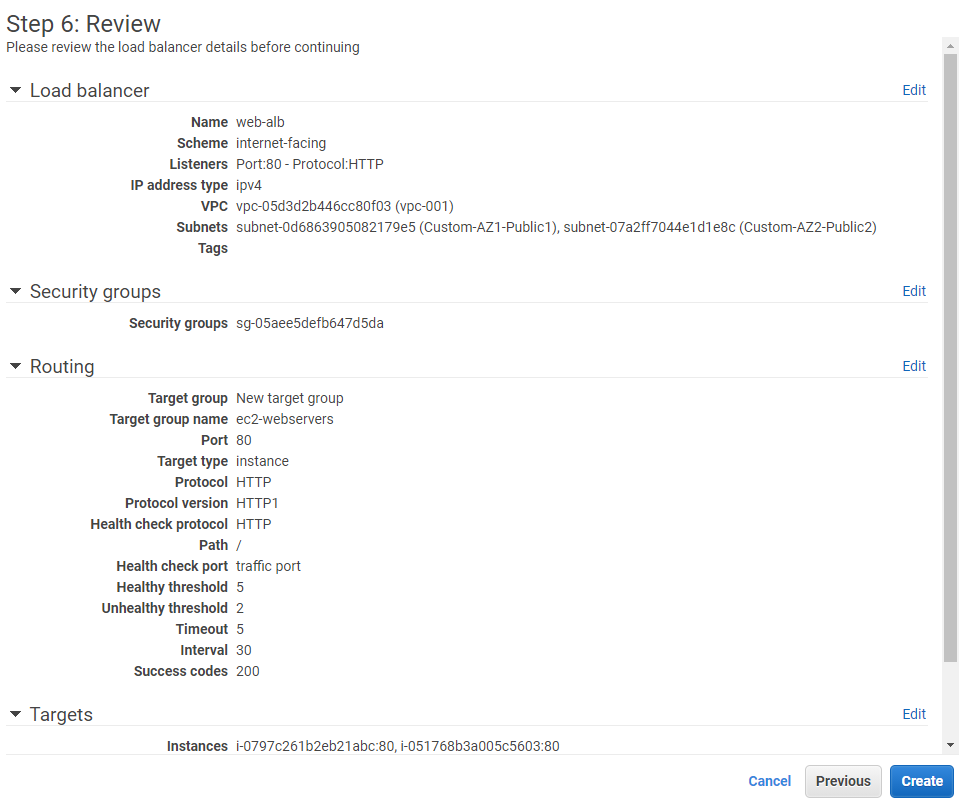
Once ASG is ready, head back to the ECS cluster dashboard and click on Cluster name. On a cluster detail page, you should see a tab named Capacity Providers. Click on it and then click on Create button.

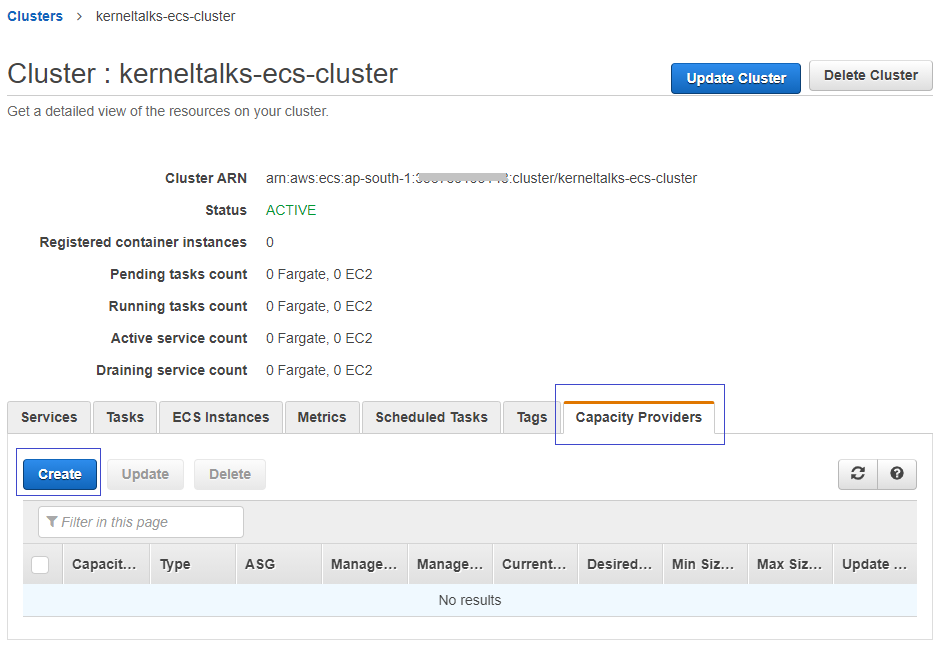
You should be presented with the Capacity Provider configuration page. Here you can specify –
- Capacity provider name: Identifier
- Auto Scaling group: Select newly created ASG from the dropdown.
- Managed scaling: Enabled so that capacity providers can manage both scales in and scale-out.
- Target capacity %: It defines how much capacity you want to be used for the task’s compute requirements. I chose 100% that means I don’t want the capacity providers to maintain any spare capacity for upcoming tasks. For example, if you specify 70%, then the capacity provider maintains 30% capacity spare so that any new upcoming tasks can directly be placed here and don’t need to wait in a PROVISIONING state for long. For optimum billing experience, 100% should be good enough.
- Managed termination protection: Enabled. It prevents ASG from terminating any instance running at least one task on it during scale-in action. Your ASG should have instance scale-in protection enabled for it.

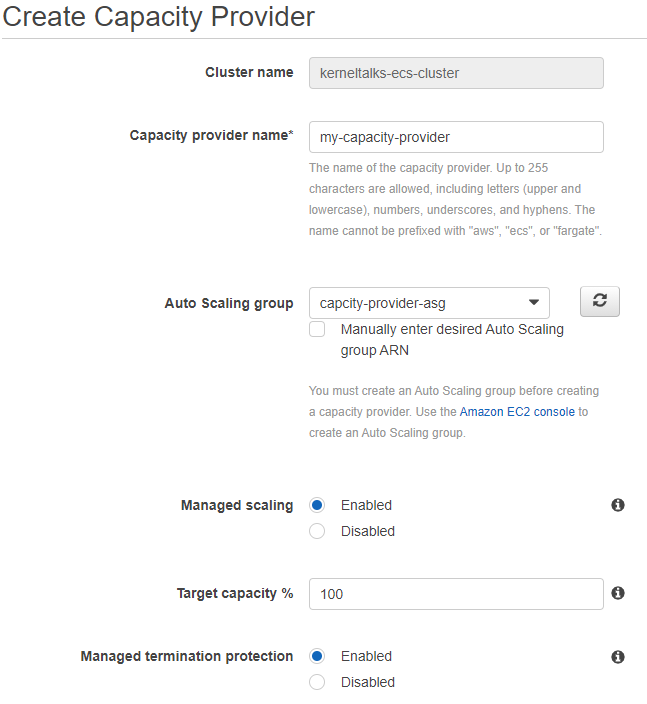
Click on Create button to create your capacity provider. You should be able to see the capacity provider on the cluster details page now.

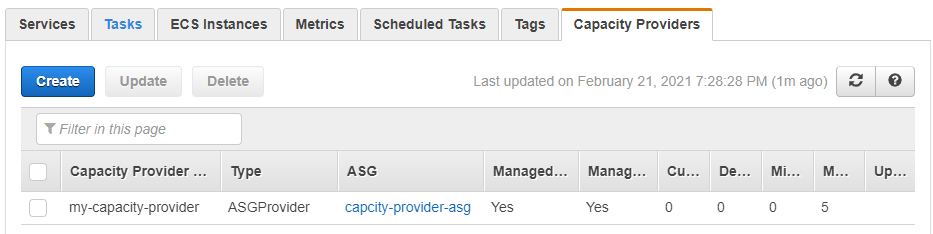
Now, it’s time to add this capacity provider to the ECS cluster.
You can create multiple capacity providers with different ASGs so that you can leverage different instance types. And they all should be listed here as well. For the sake of this article, I am moving ahead with a single capacity provider.
Click on the Update cluster button on the Cluster details page. On the update page, capacity providers can be added/removed to the cluster.

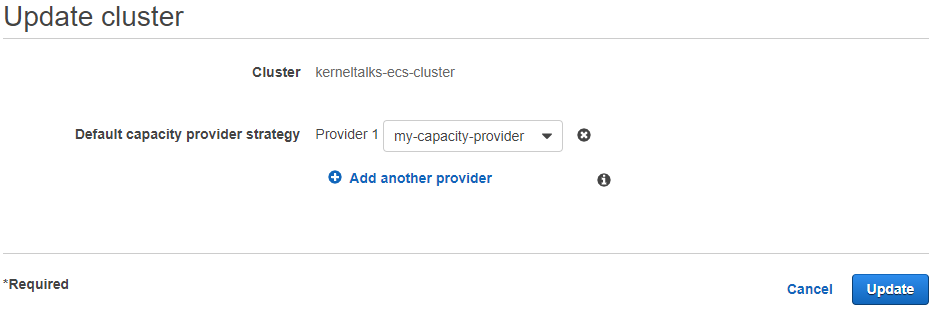
Select a capacity provider from the dropdown and click on the Update button. If you have multiple capacity providers, then add them by clicking Add, another provider.
When adding more than one capacity provider, you need to specify Base and Weight values for each capacity provider.


You should see the above message confirming capacity provider addition is successful!
Creating FARGATE capacity providers
Well, you cant create them technically! FARGATE capacity providers are readily available in FARGATE clusters. You need to associate them with the cluster.
When you create an ECS cluster backed by FARGATE, you can see FARGATE and FARGE_SPOT types of capacity providers already available in the cluster.

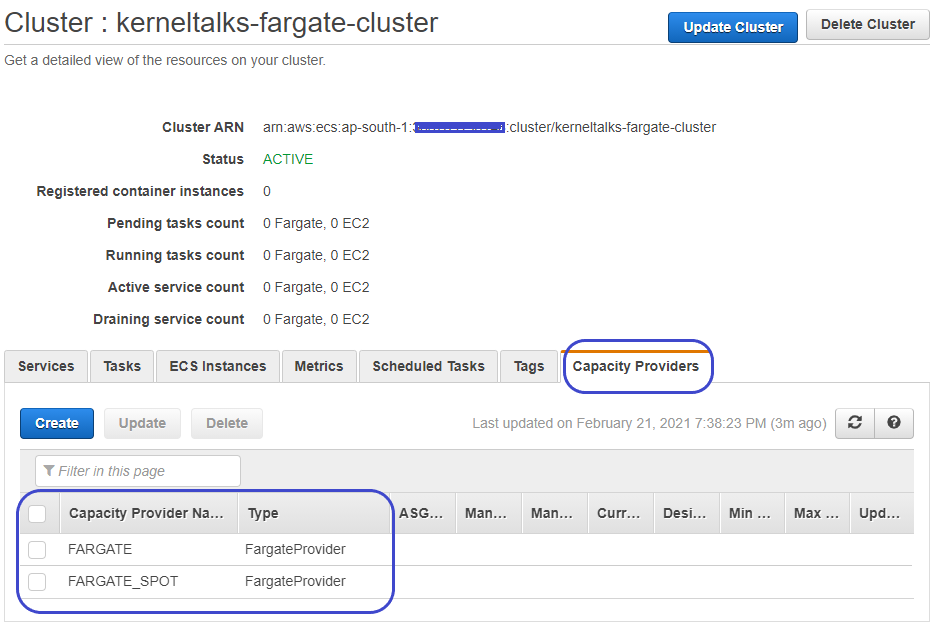
You can add them to the cluster by the same Update cluster process explained above.

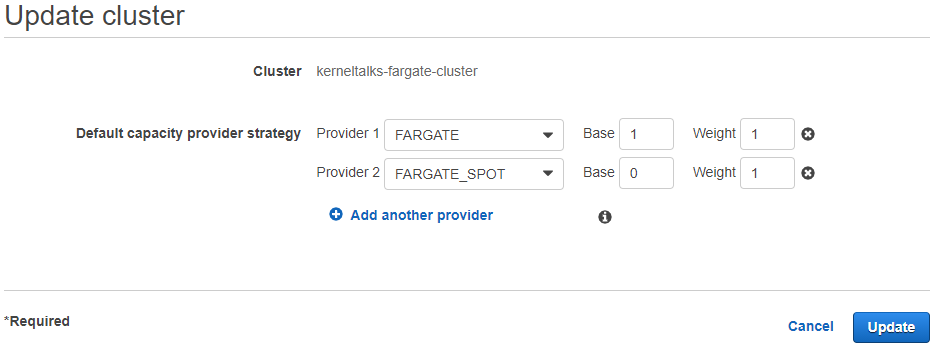
Adding FARGATE capacity providers to existing cluster
If you have an existing FARGATE ECS Cluster, you need to use AWS CLI or API calls to update it with the FARGATE capacity providers.
You need to use the put-cluster-capacity-providers switch—more details on AWS documentation here. Since I don’t have any existing FARGATE cluster, I can not demonstrate it here.
Now, your cluster is updated with capacity providers and ready to run tasks on a complete auto-scaled ECS cluster!