Learn different process states in Linux. Guide explaining what are they, how to identify them, and what do they do.
Different process states
In this article we will walk you through different process states in Linux. This will be helpful in analyzing processes during troubleshooting. Process states define what process is doing and what it is expected to do in the near time. The performance of the system depends on a major number of process states.
From birth (spawn) till death (kill/terminate or exit), the process has a life cycle going through several states. Some processes exist in process table even after they are killed/died, those processes are called zombie processes. We have seen much about the zombie process in this article. Let’s check different process states now. Broadly process states are :
Running or Runnable
Sleeping or waiting
Stopped
Zombie
How to check process state
top command lists total count of all these states in its output header.
See highlighted row named Tasks above. It shows the total number of processes and their state-wise split up.
Later in above top output observe column with heading S. This column shows process states. In the output we can see 2 processes in the sleeping state.
You can even use ps command to check process state. Use below syntax :
# ps -o pid,state,command
PID S COMMAND
1661 S sudo su -
1662 S su -
1663 S -bash
1713 R ps -o pid,state,command
In the above output you can see column titled S shows state of the process. We have here 3 sleeping and one running process. Let’s dive into each state.
Process state: Running
The most healthy state of all. It indicates the process is active and serving its requests. The process is properly getting system resources (especially CPU) to perform its operations. Running process is a process which is being served by CPU currently. It can be identified by state flag R in ps or top output.
The runnable state is when the process has got all the system resources to perform its operation except CPU. This means the process is ready to go once the CPU is free. Runnable processes are also flagged with state flag R
Process state: Sleeping
The sleeping process is the one who waits for resources to run. Since its on the waiting stand, it gives up CPU and goes to sleep mode. Once its required resource is free, it gets placed in the scheduler queue for CPU to execute. There are two types of sleep modes: Interruptible and Uninterruptible
Interruptible sleep mode
This mode process waits for a particular time slot or a specific event to occur. If those conditions occur, the process will come out of sleep mode. These processes are shown with state S in ps or top output.
Uninterruptible sleep mode
The process in this sleep mode gets its timeout value before going to sleep. Once the timeout sets off, it awakes. Or it awakes when waited-upon resources become available for it. It can be identified by the state D in outputs.
Process state : Stopped
The process ends or terminates when they receive the kill signal or they enter exit status. At this moment, the process gives up all the occupied resources but does not release entry in the process table. Instead it sends signals about termination to its parent process. This helps the parent process to decide if a child is exited successfully or not. Once SIGCHLD received by the parent process, it takes action and releases child process entry in the process table.
Process state: Zombie
As explained above, while the exiting process sends SIGCHLD to parents. During the time between sending a signal to parent and then parent clearing out process slot in the process table, the process enters zombie mode. The process can stay in zombie mode if its parent died before it releases the child process’s slot in the process table. It can be identified with Z in outputs.
So complete life cycle of process can be circle as –
Insights of Bash fork bomb. Understand how the fork bomb works, what it could to your system, and how to prevent it.
Insight of Bash fork bomb
We will be discussing Bash fork bomb in this article. This article will walk you through what is fork bomb, how it works, and how to prevent it from your systems. Before we proceed kindly read the notice carefully.
Caution: Fork bomb may crash your system if not configured properly. And also can bring your system performance down hence do not run it in production/live systems.
Fork bombs are normally used to test systems before sending them to production/live setup. Fork bombs once exploded can not be stopped. The only way to stop it, to kill all instances of it in one go or reboot your system. Hence you should be very careful when dropping it on the system, since you won’t be able to use that system until you reboot it. Let’s start with insights into the fork bomb.
What is fork bomb?
Its a type of DoS attack (Denial of Service). Little bash function magic! Fork bomb as the name suggests has the capability to fork its own child processes in system indefinably. Means once you start fork bomb it keeps on spawning new processes on the system. These new processes will stay alive in the background and keeps eating system resources until the system hangs. Mostly these new processes don’t do anything and keep idle in the background. Also, by spawning new processes it fills up the kernel process limit, and then the user won’t be able to start any new process i.e. won’t be able to use the system at all.
How fork bomb works?
Now, technically speaking: fork bomb is a function. It calls himself recursively in an indefinite loop. Check the below small example :
bombfn ()
{
bombfn | bombfn &
}
bombfn
Above is the smallest variant of the fork bomb function. Going step by step to read this code :
bombfn () : Line one is to define new function named bombfn.
{ and } : Contains the function code
bombfn : This last line calls the function (bombfn) to execute
Now the function code within { } – Here the first occurrence of bombfn means function calls himself within him i.e. recursion. Then its output is piped to another call of the same function. Lastly & puts it in background.
Overall, the fork bomb is a function which calls itself recursively, piped output to another call to himself, and then put it in background. This recursive call makes this whole process repeat itself for indefinite time till system crashes due to resource utilization full.
This function can be shortened as :(){ :|: & };:Observe carefully, bombfn is above example is replaced by : and the last call of function is inlined with ;
:(){ :|: & };:
Since this seems just a handful of symbols, the victim easily fell for it thinking that even running it on terminal won’t cause any harm as anyway, it will return an error. But it’s not!
How to prevent bash fork bomb?
Fork bomb can be prevented by limiting user processes. If you don’t allow the user to fork many processes then fork bomb won’t be allowed to spawn many processes that could bring down the system. But yes it may slow down system and user running fork bomb won’t be able to run any commands from his session.
Caution : This solution works for non-root accounts only.
Process limit can be set under /etc/security/limits.conf or PAM configuration.
To define process limit add below code in /etc/security/limits.conffile :
user1 soft nproc XXX
user1 hard nproc YYYYY
Where :
user1 is username for which limits are being defined
soft and hard are the type of limits
nproc is variable for process limit
last numbers (XXX, YYYYY) are a total number of processes a user can fork. Set them according to your system capacity.
You can verify the process limit value of user by running ulimit -u from the user’s login.
Once you limit processes and run fork bomb, it will show you below warning until you kill it. But you will be able to use the system properly provided you set limits well within range.
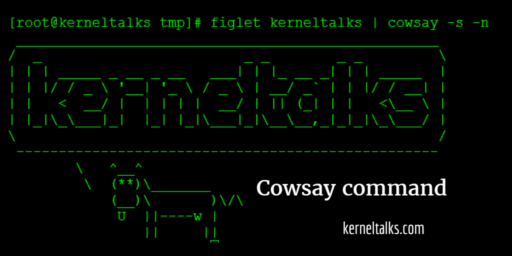
Cowsay command to have some ASCII graphics in your Linux terminal! This command displays strings of your choice as a cow is saying/thinking in graphical format.
Cowsay command!
Another article to have some fun in the Linux terminal. Previously we have seen how to create fancy ASCII banners and matrix falling code in Linux terminal. In this article we will see another small utility called cowsay which prints thinking cow ASCII picture on the terminal with a message of your choice. Cowsay is useful to write eye-catchy messages to users in motd (message of the day)!
From the man page “Cowsay generates an ASCII picture of a cow saying something provided by the user. If run with no arguments, it accepts standard input, word-wraps the message given at about 40 columns, and prints the cow saying the given message on standard output.” That explains the functionality of cowsay. Let’s see it in action!
# cowsay I love kerneltalks.com
________________________
< I love kerneltalks.com >
------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
# yum install cowsay
Loaded plugins: amazon-id, rhui-lb, search-disabled-repos, security
Setting up Install Process
epel/metalink | 12 kB 00:00
epel | 4.2 kB 00:00
http://mirror.math.princeton.edu/pub/epel/6/x86_64/repodata/repomd.xml: [Errno -1] repomd.xml does not match metalink for epel
Trying other mirror.
epel | 4.3 kB 00:00
epel/primary_db | 5.9 MB 00:09
rhui-REGION-client-config-server-6 | 2.9 kB 00:00
rhui-REGION-rhel-server-releases | 3.5 kB 00:00
rhui-REGION-rhel-server-releases-optional | 3.5 kB 00:00
rhui-REGION-rhel-server-rh-common | 3.8 kB 00:00
Resolving Dependencies
--> Running transaction check
---> Package cowsay.noarch 0:3.03-8.el6 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
=============================================================================================================================================================
Package Arch Version Repository Size
=============================================================================================================================================================
Installing:
cowsay noarch 3.03-8.el6 epel 25 k
Transaction Summary
=============================================================================================================================================================
Install 1 Package(s)
Total download size: 25 k
Installed size: 31 k
Is this ok [y/N]: y
Downloading Packages:
cowsay-3.03-8.el6.noarch.rpm | 25 kB 00:00
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : cowsay-3.03-8.el6.noarch 1/1
Verifying : cowsay-3.03-8.el6.noarch 1/1
Installed:
cowsay.noarch 0:3.03-8.el6
Complete!
Once successfully installed you can run cowsay command followed by the text you want the cow to say! There are different cow modes which you can use to change the appearance of cow 😀 (outputs later in this post)
-b: borg mode
-d: Cow appears dead
-g: greedy mode
-s: stoned cow
-t: tired cow
-y: Young cow 😛
Different Cowsay command examples
Normally cowsay word wraps. If you want fancy banners in cowsay you should use -n switch so that cowsay won’t word wrap and you get nice formatted output.
If you observe in all different modes eyes and tongues are the only entities that change. So, you can define and change them manually too! You can define eyes with -e switch and tongue with -T switch.
Learn how to set up debugging to generate NFS logs. By default NFS daemon does not provide a dedicated log file. So you have to setup debugging.
Capturing NFS logs
One of our readers asked me to query that where are NFS logs are located? I decided to write this post then to answer his query since it’s not easy to just name a log file. There is a process you need to execute well in advance to capture your NFS logs. This article will help you to find answers for where are my NFS logs? Find the NFS log file location or where NFS daemon logs events?
There is NFS logging utility in Solaris called nfslogd (NFS transfer logs). It has a configuration file /etc/nfs/nfslog.conf and stores logs in a file /var/nfs/nfslog. But, I am yet to see/use it in Linux (if it does exist for Lx). If you any insight about it, let me know in the comments.
By default, NFS daemon does not have a dedicated log file whose configuration can be done while you setup the NFS server. You need to enable debugging for NFS daemon so that its events can be logged in /var/log/messages syslog logfile. Sometimes, even without this debugging enabled few events may be logged to Syslog. These logs are not enough when you try to troubleshoot NFS related errors. So we need to enable debugging for NFS daemon and plenty handful of information will be available for you to analyze when to start NFS troubleshooting.
Below are NFS service start-stop logs in Syslog when debugging is not enabled
Jun 24 00:31:24 kerneltalks.com rpc.mountd[3310]: Version 1.2.3 starting
Jun 24 00:31:24 kerneltalks.com kernel: NFSD: Using /var/lib/nfs/v4recovery as the NFSv4 state recovery directory
Jun 24 00:31:24 kerneltalks.com kernel: NFSD: starting 90-second grace period
Jun 24 00:31:46 kerneltalks.com kernel: nfsd: last server has exited, flushing export cache
Jun 24 00:31:46 kerneltalks.com rpc.mountd[3310]: Caught signal 15, un-registering and exiting.
rpcdebug is the command used to set NFS & RPC debug flags? This command supports below switch :
-m: specify modules to set or clear
-s: set given debug flags
-c: Clear flags
Pretty simple! If you want to enable debugging use -s, if you want to turn off/disable debugging use -c! Below is a list of important debug flags you can set or clear.
nfs: NFS client
nfsd: NFS server
NLM : Network lock manager of client or server
RPC : Remote procedure call module of client or server
Enable debugging for NFS logs :
Use the below command to enable NFS logs. Here are enabling all modules. You can instead use the module of your requirement from the above list instead of all.
In the above output you can see its enabled list of modules for debugging (on right) for daemon nfsd (on left). Once this is done you need to restart your NFS daemon. After restarting you can check Syslog and voila! There are your NFS logs!
Jun 24 00:31:46 kerneltalks.com kernel: nfsd: last server has exited, flushing export cache
Jun 24 00:31:46 kerneltalks.com rpc.mountd[3310]: Caught signal 15, un-registering and exiting.
Jun 24 00:32:03 kerneltalks.com kernel: svc_export_parse: '-test-client- /shareit 3 8192 65534 65534 0'
Jun 24 00:32:03 kerneltalks.com rpc.mountd[3496]: Version 1.2.3 starting
Jun 24 00:32:03 kerneltalks.com kernel: set_max_drc nfsd_drc_max_mem 962560
Jun 24 00:32:03 kerneltalks.com kernel: nfsd: creating service
Jun 24 00:32:03 kerneltalks.com kernel: nfsd: allocating 32 readahead buffers.
Jun 24 00:32:03 kerneltalks.com kernel: NFSD: Using /var/lib/nfs/v4recovery as the NFSv4 state recovery directory
Jun 24 00:32:03 kerneltalks.com kernel: NFSD: starting 90-second grace period
Logs follow standard Syslog format. Date, time, hostname, service, and finally message. You can compare these logs with logs given at the start of this post when debugging was not enabled. You can see there are pretty extra logs are being generated by debugging.
Disable debugging for NFS logs
Disabling debugging will stop logging NFS daemon logs. It can be done with -c switch.
# rpcdebug -m nfsd -c all
nfsd <no flags set>
You can see, command clears all set flags and shows no flags set for nfsd to log any debug messages.
Learn to rescan disk in Linux VM when its backed vdisk in VMware is extended. This method does not require downtime and no data loss.
Re-scan vdisk in Linux
Sometimes we get a disk utilization situations and needs to increase disk space. In the VMware environment, this can be done on the fly at VMware level. VM assigned disk can be increased in size without any downtime. But, you need to take care of increasing space at OS level within VM. In such a scenario we often think, how to increase disk size in Linux when VMware disk size is increased? or how to increase mount point size when vdisk size is increased? or steps for expanding LVM partitions in VMware Linux guest? or how to rescan disk when vdisk expanded? We are going to see steps to achieve this without any downtime.
In our example here, we have one disk /dev/sdd assigned to VM of 1GB. It is part of volume group vg01 and mount point /mydrive is carved out of it. Now, we will increase the size of the disk to 2GB at VMware level and then will add up this space in the mount point /mydrive.
If you re using the whole disk in LVM without any fdisk partitioning, then skip step 1 and step 3.
Step 1:
See below fdisk -l output snippet showing disk /dev/sdd of 1GB size. We have created a single primary partition on it /dev/sdd1 which in turn forms vg01 as stated earlier. Always make sure you have data backup in place of the disk you are working on.
Disk /dev/sdd: 1073 MB, 1073741824 bytes
255 heads, 63 sectors/track, 130 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x8bd61ee2
Device Boot Start End Blocks Id System
/dev/sdd1 1 130 1044193+ 83 Linux LVM
# ll /mydrive
total 24
drwx------. 2 root root 16384 Jun 23 11:00 lost+found
-rw-r--r--. 1 root root 0 Jun 23 11:01 shri
drwxr-xr-x. 3 root root 4096 Jun 23 11:01 .
dr-xr-xr-x. 28 root root 4096 Jun 23 11:04 ..
Step 2:
Now, change disk size at VMware level. We are increasing it by 1 more GB so the final size is 2GB now. At this stage disk need to be re-scanned in Linux so that kernel identifies this size change. Re-scan disk using below command :
echo 1>/sys/class/block/sdd/device/rescan
OR
echo 1>/sys/class/scsi_device/X:X:X:X/device/block/device/rescan
Make sure you use the correct disk name in command (before rescan). You can match your SCSI number (X:X:X:X) with VMware disk using this method.
Note : Sending “– – -” to /sys/class/scsi_host/hostX/scan is scanning SCSI host adapters for new disks on every channel (first -), every target (second -), and every device i.e. disk/lun (third -) i.e. CTD format. This will only help to scan when new devices are attached to the system. It will not help us to re-scan already identified devices.
That’s why we have to send “1” to /sys/class/block/XYZ/device/rescan to respective SCSI block device to refresh device information like the size. So this will be helpful here since our device is already identified by the kernel but we want the kernel to re-read its new size and update itself accordingly.
Now, kernel re-scan disk and fetch its new size. You can see new size is being shown in your fdisk -l output.
Disk /dev/sdd: 2147 MB, 2147483648 bytes
255 heads, 63 sectors/track, 261 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x8bd61ee2
Device Boot Start End Blocks Id System
/dev/sdd1 1 130 1044193+ 83 Linux LVM
Step 3:
At this stage, our kernel know the new size of the disk but our partition (/dev/sdd1) is still of old 1GB size. This left us no choice but to delete this partition and re-create it again with full size. Make a note here your data is safe and make sure your (old & new) partition is marked as Linux LVM using hex code 8e or else your will mess up the whole configuration.
Delete and re-create partition using fdisk console as below:
# fdisk /dev/sdd
Command (m for help): d
Selected partition 1
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-261, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-261, default 261):
Using default value 261
Command (m for help): t
Selected partition 1
Hex code (type L to list codes): 8e
Command (m for help): p
Disk /dev/xvdf: 2147 MB, 2147483648 bytes
255 heads, 63 sectors/track, 261 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x8bd61ee2
Device Boot Start End Blocks Id System
/dev/sdd1 1 261 2095458+ 83 Linux LVM
All fdisk prompt commands are highlighted in the above output. Now you can see the new partition /dev/sdd1 is of 2GB size. But this partition table is not yet written to disk. Use w command at fdisk prompt to write table.
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
You may see the warning and error like above. If yes, you can use partprobe -s and you should be good. If you still below error with partprobe then you need to reboot your system (which is sad ).
Warning: WARNING: the kernel failed to re-read the partition table on /dev/sdd (Device or resource busy). As a result, it may not reflect all of your changes until after reboot.
Step 4:
Now rest of the part should be tackled by LVM. You need to resize PV so that LVM identifies this new space. This can be done with pvresize command.
As new PV size is learned by LVM you should see free/extra space available in VG.
# vgdisplay vg01
--- Volume group ---
VG Name vg01
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 2.00 GiB
PE Size 4.00 MiB
Total PE 511
Alloc PE / Size 250 / 1000.00 MiB
Free PE / Size 261 / 1.02 GiB
VG UUID 0F8C4o-Jvd4-g2p9-E515-NSps-XsWQ-K2ehoq
Listing of important Linux log files and their formats. These logs play a vital role in troubleshooting and every sysadmin should be aware of them.
Important log files in Linux
Troubleshooting any issues with your system needs proper knowledge of log file structure and their locations. As a sysadmin you should know for which log file should be checked for a particular service issue. In this article we will walk through several hand-picked log files which are pretty much helpful for conducting preliminary analysis during troubleshooting. 10 log files we selected to discuss here are :
/var/log/messages : General message and system related stuff
/var/log/boot.log : Services success/failures at boot
/var/log/secure or /var/log/auth.log : Authentication log
/var/log/utmp or /var/log/wtmp : Login records
/var/log/btmp : Failed login records
/var/log/cron : Scheduler log file
/var/log/maillog : Mail logs
/var/log/xferlog : File transfer logs
/var/log/lastlog : Last login details
dmesg : Device driver messages
/var/crash logs : System crash dump
Lets see each log file one by one.
System consolidated log file : /var/log/messages
All system services which do not have their own special log file, normally write to this log file. Most of the system activity can be seen here hence its also called Syslog (system’s log). Every sysadmin first opens up this log when he starts troubleshooting! Sample log looks like below :
May 22 02:00:29 server1 rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="999" x-info="http://www.rsyslog.com"] exiting on signal 15.
May 22 02:00:29 server1 kernel: imklog 5.8.10, log source = /proc/kmsg started.
May 22 02:00:29 server1 rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="1698" x-info="http://www.rsyslog.com"] start
May 22 02:17:43 server1 dhclient[916]: DHCPREQUEST on eth0 to 172.31.0.1 port 67 (xid=0x445faedb)
File can be read from left as:
Date
Time
System hostname
Service name (and sometimes PID as well)
Message text
System hostname stands value when you have a centralized Syslog server. Message text and service name help you narrow your search. You can directly grep on this file to find specific service-related logs omitting other clutter. All file operations like cat, more, less, etc can be done on this file since its plain text file.
Since this log fills very fast on a busy system (as it logs almost everything), you should consider configuring logrotate for it so that it won’t full your mount point.
Service success/failures at boot : /var/log/boot.log
At the time of booting Linux server, you can see services being started and their success or failure status is displayed on local console. The same logs can be obtained from the boot log post-boot. This file lists all service’s success/failure status at boot time so that it can be referred later to troubleshoot any service-related issues.
$ cat /var/log/boot.log
growroot: FAILED: GPT partition found but no sgdisk
Welcome to Red Hat Enterprise Linux Server
Starting udev: udevd[404]: can not read '/etc/udev/rules.d/75-persistent-net-generator.rules'
udevd[404]: can not read '/etc/udev/rules.d/75-persistent-net-generator.rules'
[ OK ]
Setting hostname ip-172-31-1-120.ap-south-1.compute.interna[ OK ]
Setting up Logical Volume Management: [ OK ]
Checking filesystems
/dev/xvda1: clean, 77980/393216 files, 811583/1572864 blocks
[ OK ]
Remounting root filesystem in read-write mode: [ OK ]
Mounting local filesystems: [ OK ]
Enabling local filesystem quotas: [ OK ]
Enabling /etc/fstab swaps: [ OK ]
Entering non-interactive startup
The above sample, file shows services, their status (on right), and any error/warning messages written to console (by service daemons).
This log file is crucial to check user access logs. Log files stores information on user logins along with authentication used. It also stores sudo logs.
Jun 14 23:41:00 server1 sshd[1586]: Accepted publickey for ec2-user from 59.184.130.135 port 51265 ssh2
Jun 14 23:41:01 server1 sshd[1586]: pam_unix(sshd:session): session opened for user ec2-user by (uid=0)
Jun 14 23:41:04 server1 sudo: ec2-user : TTY=pts/0 ; PWD=/home/ec2-user ; USER=root ; COMMAND=/bin/su -
Jun 14 23:41:04 server1 su: pam_unix(su-l:session): session opened for user root by ec2-user(uid=0)
Jun 14 23:43:45 server1 su: pam_unix(su-l:session): session closed for user root
Log file can be read from left to right as :
Date
Time
Server hostname
Authentication service or daemon (sometimes along with PID)
Message
Login records : /var/log/utmp, /var/log/wtmp
These wtmp or utmp file stores user login details. utmp stores login details like id, time, duration, the terminal used, system reboot details, etc. wtmp provides historical utmp data. These files are not plain text files and hence need to be parsed to last command to read data within. You can use last -f <path> to read file.
ec2-user pts/1 59.184.170.243 Mon Jun 19 07:24 still logged in
ec2-user pts/0 59.184.170.243 Mon Jun 19 07:21 - 07:24 (00:02)
reboot system boot 2.6.32-696.el6.x Mon Jun 19 07:20 - 07:39 (00:18)
ec2-user pts/0 59.184.130.135 Wed Jun 14 23:41 - 00:09 (00:28)
reboot system boot 2.6.32-696.el6.x Wed Jun 14 23:40 - 00:09 (00:29)
In above output of last -f /var/log/wtmpyou can see from left to right :
User or event (reboot)
Terminal used
IP from which user was connected
Date/time of login
Date /time of log out
Duration of session
Failed login records : /var/log/btmp
Its file dedicated to logging only failed login attempts. This too can be read using last command as mentioned above.
user1 ssh:notty 31.207.47.50 Tue Jun 13 01:18 gone - no logout
user ssh:notty 31.207.47.50 Tue Jun 13 01:18 - 01:18 (00:00)
ubnt ssh:notty 31.207.47.50 Tue Jun 13 01:18 - 01:18 (00:00)
It also shows user id, terminal, source IP, and time who tried to log into the system but failed to do so.
Scheduler logs : /var/log/cron
Cron (Linux scheduler) logs are saved under /var/log/cron. Job run status, daemon logs are saved here. It helps in understanding job execution and troubleshooting of scheduled jobs. Its plain text file and supports all normal file operations.
Jun 15 00:09:51 server1 crond[1473]: (CRON) INFO (Shutting down)
Jun 19 07:21:18 server1 crond[1474]: (CRON) STARTUP (1.4.4)
Jun 19 07:21:18 server1 crond[1474]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 26% if used.)
Jun 19 07:21:20 server1 crond[1474]: (CRON) INFO (running with inotify support)
Jun 19 07:30:01 server1 CROND[1676]: (root) CMD (/usr/lib64/sa/sa1 1 1)
Jun 19 07:40:01 server1 CROND[1702]: (root) CMD (/usr/lib64/sa/sa1 1 1)
Since the server was shut on 15 Jun and started on 19 Jun you can see cron daemon wrote down and up logs in this log file. For job executed, log code CMD is used. Daemon messages are tagged with INFO.
Mail logs : /var/log/maillog
Mail related logs saved here. It logs date-time, hostname, mail protocol (with PID sometimes), and messages.
Jun 15 00:09:51 server1 postfix/postfix-script[1939]: stopping the Postfix mail system
Jun 15 00:09:51 server1 postfix/master[1432]: terminating on signal 15
Jun 19 07:21:17 server1 postfix/postfix-script[1432]: starting the Postfix mail system
Jun 19 07:21:17 server1 postfix/master[1433]: daemon started -- version 2.6.6, configuration /etc/postfix
Since our server doesn’t have an SMTP configuration, there is nothing much in our file shown above.
File transfer logs : /var/log/xferlog
This log contains information from file transfer program/service daemons.
Mon Jun 19 04:44:43 2017 1 10.4.1.22 20 /CSV/test1.csv a _ o r testuser ftp 0 * c
Mon Jun 19 04:51:33 2017 1 10.4.1.22 432 /CSV/test4.csv a _ o r testuser ftp 0 * c
Mon Jun 19 04:57:15 2017 1 10.4.1.22 110 /CSV/test14.csv a _ o r testuser ftp 0 * c
Mon Jun 19 04:57:19 2017 1 10.4.1.22 2505 /CSV/master.csv a _ o r testuser ftp 0 * c
Sample log files hows date, time, source IP, file path copied, options used, the user who copied files, the protocol used details.
Last login details : /var/log/lastlog
System’s all user’s recent login details are saved to this log file. Its not plain text file and hence you need to use lastlog command which reads data from this log file and print on the terminal in a human-readable format. It sorts users with their order in /etc/passwd file.
# lastlog
Username Port From Latest
root **Never logged in**
bin **Never logged in**
oprofile **Never logged in**
tcpdump **Never logged in**
ec2-user pts/1 59.184.170.243 Mon Jun 19 07:24:14 -0400 2017
apache **Never logged in**
Above output is pretty self explanatory.
Device driver messages : dmesg
Boot time device/driver writes messages on the console. Those messages can be viewed as post boot as well using dmesg command. These messages help in troubleshooting devices or driver initialization issues.
Those are all boot time messages just before /var/log/boot.log
System crash dump : /var/crash
This is the directory under which the core-dump is saved in case of a system crash. Obviously you need to configure dump configs on the system for it. This information is very important to get the root cause of the system crash. This is almost the image of the current state of the system at the time of the crash. Most of the vendor asks this dump files to analyze when we log a case with them for a system crash.
KernelTalks implemented few blog enhancements for better SEO and reader engagement. Addition of SSL, AMP & browser push notifications to blog
SSL, AMP and notification! Blog enhancements.
A few months ago we did blog enhancement for better speed and cleaner look by adding premium theme built on Genesis framework and CDN support for lightning-fast page loads. This month we are adding a few more enhancements and features to blog which helps us build better SEO and people engagement.
SSL support
We have added SSL support to our blog. Now kerneltalks.com loads over https protocol (more secured). Information sends to us will be secured over the internet. Since many of you already know, SSL is one more factor to rank pages in search by Google. This implementation will help us building good ranks in Google search results and building more organic traffic.
Blog is now AMP ready
Google in recent times declared AMP (Accelerated mobile pages) as one of the ranking factors. AMp ensures loading pages on mobile devices almost in no time. This is done via removing all scripts, styling, and very limited special HTML tagging of page. KernelTalks now AMP ready! Now our posts are listed in google results with AMP lightning icon!
AMP pages
You can even view the amp version of kerneltalks by appending /amp to any of our URLs in the browser. We are more closer to the audience with lower bandwidth and loading our pages lightning fast even on mobile devices. If you want to customize and stylish your AMP pages try plugin named AMP for WP. It has all customization you need along with the option to configure AdSense ads.
Browser push notifications
One more reader engagement option enabled for kerneltalks. We have started browser push notifications (supports Chrome, Firefox, Safari) which will notify you about our new articles whenever you open up your browser. You can opt into these notifications by clicking allow in a popup window when you now visit kerneltalks.com. We are using Onesignal push utility for this. This is the best free service allowing unlimited subscribers so you can go for it if you are looking for one for your blog.
That’s all for now! Keep blogging! Let us know your feedback about our blog in the comments.
Learn how to create, view, and remove command alias in Linux or Unix. Useful to shorten long commands or imposing switches to commands.
Command alias
Command alias in Linux is another (mostly short) version of frequently used command (or command with arguments). It is meant for lessening keystrokes to type long commands and making it fast, easy, and accurate to work in shell. On the other hand, if you want users to use some commands with preferred switch always, you can create an alias of it. For example, rm command can be aliased to rm -i so that it will be always interactive asking the user to confirm his remove operation.
In this article we will see how to create command alias, how to remove the alias, and how to list alias.
How to create alias
Creating alias is an easy job. You have to specify alias and command to alias like below :
# alias ls='ls -lrt'
Here in this example, we are aliasing command ls to ls -lrt so that whenever we type ls command it will long list, reverse order with a timestamp. Saving out time to write long command with arguments. See how differently ls works before and after alias in the below output.
# ls
apache httpd-2.4.25 httpd-2.4.25.tar letsencrypt lolcat-master master.zip shti
# alias ls='ls -lrt'
# ls
total 38504
-rw-r--r--. 1 root root 39198720 Dec 19 12:29 httpd-2.4.25.tar
drwxr-xr-x. 5 root root 4096 Dec 26 07:48 lolcat-master
-rw-r--r--. 1 root root 205876 Mar 22 02:21 master.zip
drwxr-xr-x. 2 root root 4096 Mar 29 08:15 apache
drwxr-xr-x. 12 501 games 4096 Mar 29 08:42 httpd-2.4.25
drwxr-xr-x. 14 root root 4096 Apr 3 15:07 letsencrypt
drwxr-xr-x. 2 root root 4096 May 16 01:29 shti
Make a note that this alias will be available in the current shell only. If you want to make it permanent over reboots, spawns over other users and shells then you need to define it in /etc/profile or respective shell profiles of the individual users. Defining it in profiles is the same syntax, just add the above command in a profile file and it will works once the profile is sourced.
List alias in current shell
To view and list all aliases currently active in your shell, just type command alias without any argument.
# alias
alias cp='cp -i'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls -lart'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
In the above output you can see all commands on the left of = and values they are aliased for in the right section. These aliases are defined on /etc/profile or user profiles or shell profiles or defined in the shell with alias command.
How to delete alias
In case you want to remove or delete alias you defined, you need to use unalias command. This command takes your alias command (left portion of = in the above listing) as an argument.
# unalias ls
# alias
alias cp='cp -i'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
Observe in above output after un-aliasing ls, its alias to ls -lart vanishes from alias listing. Keep in mind that this un-alias is limited to the current shell only. If you want to permanently un-alias command then you need to remove it from the profile file where you have defined it and re-source that profile.
Fun in terminal using alias
By now you know how alias works, you can play around to have some fun in the terminal. You can alias funny statements to commonly used commands. For example aliasing ls to cmatrix command to run matrix green falling code in terminal and stun user!
# alias ls=' echo I love kerneltalks.com :D'
# ls
I love kerneltalks.com :D
As you know how it can turn evil if it gets into the wrong hands! So be extra cautious when defining an alias for destructive commands.
Learn the configuration of iptables policies in Linux. Know how to add, delete, save Linux native firewall rules in iptables.
Configuring iptables policies in Linux
In our last article about iptables, we have seen the basics of iptables, iptables chains, and chain policy strategy. In this article we will walk through how to define iptables policies.
Defining iptables policies means allowing or blocking connections based on their direction of travel (incoming, outgoing or forward), IP address, range of IP addresses, and ports. Rules are scanned in order for all connections until iptables gets a match. Hence you need to decide and accordingly define rule numerically so that it gets match first or later than other rules.
In newer versions like RHEL7, the firewall is still powered by iptables only the management part is being handled by a new daemon called firewalld.
iptables is the command you need to use to define policies. With below switches –
-A: To append rule in an existing chain
-s: Source
-p: Protocol
–dport: service port
-j : action to be taken
Lets start with examples with commands.
Block/Allow single IP address
To block or allow a single IP address follow below command where we are adding a rule -A to input chain (INPUT) for blocking (-j REJECT).
In the above command we are blocking incoming connections from IP 172.31.1.122. If you see the output of rules listing, you can see our rule is defined properly in iptables. Since we didn’t mention protocol, all protocols are rejected in the rule.
Here chain can be any of the three: input (incoming connection), output (outgoing connection), or forward (forwarding connection). Also, action can be accepted, reject, or drop.
Block/Allow single IP address range
Same as single IP address, whole address range can be defined in rule too. The above command can be used only instead of IP address you need to define range there.
I have shown two different notation types to define the IP address range/subnet. But if you observe while displaying rules iptables shows you in /X notation only.
Again action and chain can be any of the three of their types as explained in the previous part.
Block/Allow specific port
Now, if you want to allow/block specific port then you need to specify protocol and port as shown below :
Here in this example we blocked the telnet port using TCP protocol from specified source IP. You can choose the chain and action of your choice depending on which rule you want to configure.
Saving iptables policies
All the configuration done above is not permanent and will be washed away when iptable services restarted or server reboots. To make all these configured rules permanent you need to write these rules. This can be done by supplying save argument to iptables service (not command!)
# /sbin/service iptables save
iptables: Saving firewall rules to /etc/sysconfig/iptables:[ OK ]
You can also use iptables-save command.
If you open up /etc/sysconfig/iptables file you will see all your rules saved there.
# cat /etc/sysconfig/iptables
# Generated by iptables-save v1.4.7 on Tue Jun 13 01:06:01 2017
*filter
:INPUT ACCEPT [32:2576]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [48:6358]
-A INPUT -s 172.31.1.122/32 -j REJECT --reject-with icmp-port-unreachable
-A INPUT -s 172.31.0.0/22 -j REJECT --reject-with icmp-port-unreachable
-A INPUT -s 172.31.0.0/23 -j REJECT --reject-with icmp-port-unreachable
-A INPUT -s 172.31.1.122/32 -p tcp -m tcp --dport 23 -j DROP
COMMIT
# Completed on Tue Jun 13 01:06:01 2017
Deleting rule in iptables
We have seen how to add a rule, how to delete the existing rules. You can use the same commands used above only change is to add -D switch instead of -A!
# iptables -D INPUT -s 172.31.1.122 -j REJECT
The above command will remove the very first rule we added in iptables in this post.
Also, if you haven’t saved your iptables you can flush all currently configured rules by using -F.
Beginner’s tutorial to understand iptables – Linux firewall. This article explains about iptable basics, different types of chains, and chain policy defining strategy.
iptables – Linux firewall
Linux firewall: iptables! plays a very important role in securing your Linux system. System hardening or locking down cannot be completed without configuring iptables. Here we are discussing the basics of iptables. This article can be referred to by beginners as an iptables guide. In this article we will walkthrough :
What is iptables
iptables chains
Chain policy defining strategy
We discussed how to set iptables rules, how to save iptables settings in this article. Let’s start with iptables basics.
What is iptables
iptables is a Linux native firewall and almost comes pre-installed with all distributions. If by any chance its not on your system you can install an iptables package to get it. As its a firewall, it has got policies termed as ‘chain policies’ which are used to determine whether to allow or block incoming or outgoing connection to or from Linux machine. Different chains used to control the different types of connections defined by its travel direction and policies are defined on each chain type.
In newer versions like RHEL7, the firewall is still powered by iptables only the management part is being handled by a new daemon called firewalld.
As there are policies you can define, one default policy also exists for all chains. If the connection in question does not match with any of the defined policy chains then iptable applies default policy action to that connection. By default (generally) ALLOW rule is configured in defaults under iptables.
iptable chains
As we saw earlier iptables rely on chains to determine the action to be taken in connection, let’s understand what are chains. Chains are connection types defined by their travel direction/behavior. There are three types of chains: Input, Output, Forward.
Input chain :
This chain is used to control incoming connections to the Linux machine. For example, if the user tries to connect the server via ssh (port 22) then the input chain will be checked for IP or user and port if those are allowed. If yes then only the user will be connected to the server otherwise not.
Output chain :
Yes, this chain controls outgoing connections from the Linux machine. If any application or user tries to connect to outside server/IP then the output chain decides if the app/user can connect to destination IP/port or not.
Both chains are stateful. Meaning only said the connection is allowed and a response is not. Means you have to exclusively define input and output chain if your connection needs both way communication (from source to destination and back)
Forward chain :
In most of the systems, it’s not used. If your system is being used as a pass-through or for natting or for forwarding traffic then only this chain is used. When connections/packets are to be forwarded to next hop then this chain is used.
You can view the status of all these chains using the command :
# iptables -L -v
Chain INPUT (policy ACCEPT 8928 packets, 13M bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 2201 packets, 677K bytes)
pkts bytes target prot opt in out source destination
In above output, you can see all three chains details, how many packets were transferred, how much data transferred and default action policy.
Chain policy defining strategy
There are three policies can be defined for chains.
ACCEPT: Allow connection
REJECT: Block connection and send back error message informing source that destination blocked it
DROP: Block connection only (behave like connection never questioned). The source is unaware of being blocked at the destination.
By default, all chains configured with ACCEPT policy for all connections. When configuring policies manually you have to pick either way from below two :
Configure default as REJECT/DROP and exclusively configure each chain and its policy of ALLOW for required IP/subnet/ports.
Configure default as ACCEPT and exclusively configure each chain and its policy of REJECT for required IP/subnet/ports.
You will go with number two unless your system has highly sensitive, important data and should be locked out of the outer world. Obviously, its environment criticality and number of IP/subnet/ports to be allowed/denied makes it easier to select a strategy.
In next article we discussed how to define these chain policies in detail.