I am consolidating errors I came across and their solution in quick words for easy reference to me and you as well!


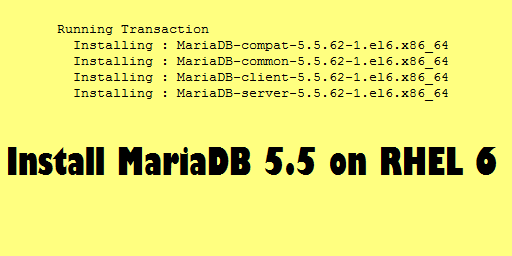
Error saw while starting the MariaDB server process on RHEL 6
# service mysql start
mysql: unrecognized service
Solution: You do not have MariaDB installed on your server. Install MariaDB
Error while starting MariaDB server process n RHEL 7
# systemctl start mariadb
Failed to issue method call: Unit mariadb.service failed to load: No such file or directory.
Solution: You do not have MariaDB installed. Install mariadb-server package
Error while installing Symantec Antivirus
which: no uudecode in (/usr/sbin:/usr/bin:/bin)
ERROR: Required utility missing: uudecode. Please install this
utility before using this Intelligent Updater package.
Solution : uudecode is provided by sharutils package. Install sharutils package.
Error while exporting a filesystem
# exportfs -ra
exportfs: 34.89.123.45:/data: Function not implemented
Solution: Check and start the nfs-server process.
Error while listing directory files
# ls -lrt
ls: cannot open directory '.': Permission denied
Solution: Your directory does not have read permission to the owner. Sometimes due to windows to Linux file copy etc. Set permission and you are good to go. Use the command in the same directory # chmod -R +r .
Error while querying NTP
# ntpq -p
localhost: timed out, nothing received
***Request timed out
Solution : Edit /etc/ntp.conf and replace restrict 127.0.0.1 to restrict localhost then restart ntpd service with systemctl restart ntpd
Error during mounting of the file system
# mount /dev/vg01/lvol0 /dump
mount: unknown filesystem type '(null)'
Solution: You are trying to mount a file system which is not formatted yet. Format filesystem and then try mounting.
Error while mounting other system’s disk
I was trying to mount a disk from another server in AWS and it was not mounting. I checked dmesg and got below error :
[ 792.138218] XFS (xvdh2): Filesystem has duplicate UUID d295b18a-2a70-4260-9f59-60e51432ea92 - can't mount
Solution: Since I was doing some research I temporarily mounted it without UUID. using below command –
root@kerneltalks # mount -t xfs -o nouuid /dev/xvdh2 /disk1
But ideally, you should have unique UUID to all disks on the system and you can generate UUID in such a case using XFS utility.
keytool command not found
keytool is used to generate key or CSR for SSL certificate.
# keytool -genkey -alias server -keyalg RSA -keystore kerneltalks.jks -keysize 2048
If 'keytool' is not a typo you can use command-not-found to lookup the package that contains it, like this:
cnf keytool
Solution: Make sure you have JRE installed (Java Runtime Environment). Goto JRE binary directory and then run this command.
java version typo
# /usr/bin/java version
Error: Could not find or load main class version
Its java trying to load the program named version. You missed hyphen there!
Solution: Try below command
# java -version
java version "1.7.0_211"
OpenJDK Runtime Environment (rhel-2.6.17.1.0.1.el7_6-x86_64 u211-b02)
OpenJDK 64-Bit Server VM (build 24.211-b02, mixed mode)
Bad magic number in super-block
Error below seen while trying to resize filesystem in RHEL7
# resize2fs /dev/mapper/vg01-data
resize2fs 1.42.9 (28-Dec-2013)
resize2fs: Bad magic number in super-block while trying to open /dev/mapper/vg01-data
Couldn't find valid filesystem superblock.
Solution: This is because RHEL7 has the XFS filesystem by default so you need to use xfs_growfs command to resize the filesystem.
# xfs_growfs /dev/vg01/data
meta-data=/dev/mapper/vg01-root isize=256 agcount=4, agsize=851968 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=3407872, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 3407872 to 7863296
How to change DocumentRoot in Apache2 to different directory than /srv/www/htdocs
Apache2 has by default DocumentRoot set to /srv/www/html. If you want to change it to some different directory you need to change it in a couple of configuration files.
Easy way to search all those files is searched in the directory –
# grep -R "DocumentRoot" /etc/apache2
# grep -R srv /etc/apche2
Here are few files and the lines within them you need to edit.
# vi /etc/apache2/default-server.conf
ScriptAlias /cgi-bin/ "/srv/www/cgi-bin/"
<Directory "/srv/www/cgi-bin">
DocumentRoot "/srv/www/htdocs"
<Directory "/srv/www/htdocs">
# vi /etc/apache2/vhosts.d/vhost-ssl.conf
DocumentRoot "/srv/www/htdocs"
You need to edit /srv/www/htdocs to directory of your choice. Also, you need to change relative directories to /srv as well. Once you are done with editing, you need to restart the apache2 service and you are good to go.
server_id_usr_crc warning in Suse Manger
Repeatedly below warning is being logged in /var/log/messages in Suse Manager server 4.0
2019-08-07T20:38:02.832696+08:00 susemgr-test salt-master[12485]: [WARNING ] /usr/lib/python3.6/site-packages/salt/grains/core.py:2815: DeprecationWarning: This server_id is computed nor by Adler32 neither by CRC32. Please use "server_id_use_crc" option and define algorithm youprefer (default "Adler32"). The server_id will be computed withAdler32 by default.
Solution : Add server_id_use_crc: adler32 entry at end of the file /etc/salt/master.d/susemanager.conf and then restart the Suse Manager process.
smdba backup fails to run in cron on SUSE Manager
smdba is a DB backup tool by SUSE to be used on Suse Manager which runs on postgres database. smdba tool to be run by root and in the backend it switches to DB user to connect with database and execute database stuff. It runs manually well but when scheduled in cron it exits with the below error.
Backend error:
Access denied to UID 'postgres' via sudo.
You can see this error in root mail or you need to redirect stderr of cron command to file and you can see it in there.
Solution: This is because the root is not able to sudo to postgres user since cron spawned process don’t have tty attached to it and your sudo most likely have Defaults requiretty active in /etc/sudoers. If you want you can disable it system-wide by putting # in front of it or add a dedicated entry for root Defaults:root !requiretty to move out of this restriction. Once done try running smdba commands via cron and they will run successfully.
/etc/resolv.conf resetting to default after reboot
Issue: My /etc/resolv.conf entries gets wiped out after reboot. Manual entries added in /etc/resolv.conf are getting deleted after reboot.
Solution: This is probably because your /etc/resolv.conf is being auto-generated by netconfig. It will be symlink to /var/run/netconfig/resolv.conf. You can disable this by setting NETCONFIG_DNS_POLICY='' in /etc/sysconfig/network/config file. It will be defined as auto, you set it to blank. Or you can edit below parameters in the same file if you want to keep the above policy parameter untouched.
NETCONFIG_DNS_STATIC_SEARCHLIST
NETCONFIG_DNS_STATIC_SERVERS
NETCONFIG_DNS_FORWARDER
Once done adjust /etc/resolv.conf by running command netconfig update -f. If after this your /etc/resolv.conf remains as it is then you are good otherwise you need to review the above settings again carefully.
If it is being reloaded by DHCP you will see below line in /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
In that case you need to perform below actions.
# vi /etc/dhcp/dhclient-enter-hooks
#!/bin/sh
make_resolv_conf(){
:
}
#chmod +x /etc/dhcp/dhclient-enter-hooks
yum command giving metadata errors
yum command showing below error :
Error while executing packages action: failed to retrieve repodata/filelists.xml.gz from Oraclelinux7-x86_64 error was [Errno -1] Metadata file does not match checksum
Solution :
Run below commands and you are good to go.
# yum clean all
# yum makecache
PAM module error
PAM unable to dlopen(/lib64/security/pam_gnome_keyring.so): /lib64/security/pam_gnome_keyring.so: cannot open shared object file: No such file or directory
PAM adding faulty module: /lib64/security/pam_gnome_keyring.so
Solution :
Update pam packages and/or install gnome-keyring package.
Account login error with LDAP
pam_sss(sudo:auth): received for user shrikant: 10 (User not known to the underlying authentication module)
Solution :
This is because account shrikant does not exists in LDAP server account list. If this is local user to that perticular client then you can add it to ignore list in LDAP config file /etc/sssd/sssdconf in below parameters.
[nss]
filter_users = root,shrikant
filter_groups = root,dba
NFS Timeout error
# mount -v -t nfs 10.10.1.2:/data /mnt/data
mount.nfs: timeout set for Wed Jan 29 08:29:01 2020
mount.nfs: trying text-based options 'vers=4,addr=10.10.1.2,clientaddr=10.10.1.3'
mount.nfs: mount(2): Connection timed out
mount.nfs: Connection timed out
Solution :
This is because client is not able to reach NFS server. There are couple of things you should check.
- TCP and UDP port 2049 and 111 should be open between client and server. Use
nc -v -u <nfs_server> port - NFS server service should be running on the server
- NFS client service should be running on the client
- If you have SEP 14 (Symantec Endpoint Protection) antivirus running on your machines then un-install and reboot both client and server.
Warning in xclock command
# xclock
Warning: Missing charsets in String to FontSet conversion
Solution:
This is just a warning about improper environment variables. You can avoid it by exporting –
export LC_ALL=C
You can add this in the user profile file as well so that it will be exported at login and no need to exporting manually.
sssd service is not starting up
After patching or system migration like activities your sssd dont start up. When you try to start sssd service you get below errors in systemd status sssd :
sssd[16866]: Exiting the SSSD. Could not restart critical service [kerneltalks.com].
systemd[1]: sssd.service: Main process exited, code=exited, status=1/FAILURE
systemd[1]: Failed to start System Security Services Daemon.
systemd[1]: sssd.service: Unit entered failed state.
systemd[1]: sssd.service: Failed with result 'exit-code'.
In such cases the best way to check actual errors is to check the log file located in /var/log/sssd/sssd*.log. You can see sssd logs as well as domain logs here. You need to check both.
In my case I got errors in domain log file –
[sssd[be[kerneltalks.com]]] [dp_target_init] (0x0010): Unable to load module krb5
[sssd[be[kerneltalks.com]]] [be_process_init] (0x0010): Unable to setup data provider [1432158209]: Internal Error
[sssd[be[kerneltalks.com]]] [main] (0x0010): Could not initialize backend [1432158209]
[sssd[be[kerneltalks.com]]] [dp_module_open_lib] (0x0010): Unable to load module [krb5] with path [/usr/lib64/sssd/libsss_krb5.so]: /usr/lib64/sssd/libsss_krb5.so: cannot open shared object file: No such file or directory
For this missing file, I installed sssd-krb5 package and my issue got resolved.
sssd service is running but user can not login
sssd service was running fine but showing below error in systemctl status sssd and the user was not able to log in –
sssd_be[2338]: GSSAPI Error: An invalid name was supplied (Success)
Solution :
Add below line under section [libdefaults] in /etc/krb5.conf
rdns = false
then restart sssd service using systemctl restart sssd